↩ 018. Mean-shift clustering ↩
Tue, 29 Apr 2025 16:32:56 +0200
Contents
- Problem statement
- [[palette, r=0.1: D=p \circ ((\mathrm{CC}_{16}, \mathrm{4E}_{16}, \mathrm{FF}_{16}), (\mathrm{FF}_{16}, \mathrm{2D}_{16}, \mathrm{FF}_{16}), (\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16}))]]
- [[*freq, r=0.1: D=p \circ \begin{pmatrix}(\mathrm{CC}_{16}, \mathrm{4E}_{16}, \mathrm{FF}_{16}) & (\mathrm{FF}_{16}, \mathrm{2D}_{16}, \mathrm{FF}_{16})\\(\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16}) & (\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16})\end{pmatrix}]]
- Base case
- rubber to the road
- base-line
- memory types
- who up branchin they execution
- Hitting the griddy? In this economy?
- Failure: GPU-side grid-cell-to-index-list mapping
- processed piece-meal.
- straight up "bussing it" and by "it", haha, well. let's justr say. My rgbs.
- our very own Enron scandal.
- Do NOT tell americans about your allocations. Worst mistake of my life.
- You do not under any circumstances have to hand it to Scott Adams
- Totally ellipsoidal, man!
- commutativity can be your angle....
- re-tuning the piece-meal iteration count
- Grid size re-evaluation
- Failure: un-nesting iteration of points-in-cell from iteration of cells-in-bounding-box
- Failure: [[l<a<b]]
- parallelising is points-in-cell assign_cell.hlsl
grouping
post-processing - de-parallelising find_bbox.hlsl
- Moral
- Network effect
In Mean Shift Clustering, Gneiss Name, 2025 ▶,
he describes a model for parametric palette reduction that appears, to me, to be best-in-class.
It's a good paper video, and this is not a replacement therefor —
this instead serves
- to
rigorouslydescribe the core algorithm in text, - to provide a general implementation — download, run, instruxions in README,
- to describe the optimisations that can be applied to this problem
- (also those that shouldn't because they lose),
- as a commentary on the state of Vulkan development "on-boarding" (I hadn't written a GPU program before this).
Compare the measured performance on my AMD Radeon RX 5700 XT THICC II/i7-2600/DDR3-1600 vs an AMD Radeon RX 6500 XT (RADV NAVI24)/5800X3D/DDR4-3600 (weighted average 14% faster) and a laptop with an iGPU (Intel(R) Iris(R) Xe Graphics (ADL GT2)/i5-1235U/SDDDR4 3200 MHz (0.3 ns)) (average 3× slower):
| (colours) | 16'755 | 84'860 | 242'931 |
|---|---|---|---|
| 5700 XT | 79.46ms | 3.35s | 36.33s |
| 6500 XT | 91.24ms | 4.00s | 31.47s |
| i5-1235U iGPU | 365.38ms | 17.85s | 118.90s |
| (colours) | 27'868 | 328'666 | 1'103'347 |
| 5700 XT | 1.11s | 43.16s | 24.48s |
| 6500 XT | 1.01s | 37.24s | 19.59s |
| i5-1235U iGPU | 4.41s | 165.40s | 60.20s |
(colour count is (clearly) not the only factor affecting speed; measurements from the test dataset). (All time figures are mean of at least 5 measurements, usually more.)
A CPU implementation processes that 16'755-colour image in 5.5s (on the i7-2600 which has 8 CPUs). The others are a "don't even dream about it" scale.
A naive GPU implementation processes it in 160ms, times out after 8s after processing ~50/242'931 colours, and times out after 8s after processing ~150/1'103'347 colours (measured from f39afc3). This can be analysed as a 2×/1080×/2450× improvement and that is basically real.
I would like to thank Cicada, rightfold, ratchetfreak and to acknowledge the prior art of shaderposting by Sebastian Lague, Acerola, and their ilk. This drew heavily on my largely-faded memory of techniques described thereby. I would like to thank Dr. Hoel Kervadec, Orson R. L. Peters and Jade Master for their notational insights.
# Problem statement
- With operator [[\circ]] as an element-wise application: [[\forall{i} : (f \circ A)_{i} = f(A_{i})]],
- with operator [[\odot]] as the Hadamard product: [[\forall{i} : (A \odot B)_{i} = A_{i}B_{i}]],
- with [[[]]] as the Iverson bracket: [[[x] = (1\text{ if }x\text{ otherwise }0)]],
- with [[\bar{\ }]] as the set of preceding naturals: [[\bar{n} = [0, n ) \cap \mathbb{Z}]],
- let colour [[C = ([0, 255] \cap \mathbb{Z})^3]],
- given input [[n]]-dimensional image [[I \in (C_i)_{i \in \mathbb{N}_+^n}]],
- construct a map [[f: C \to C]] such that
- the output image [[O]] is given by [[O = f \circ I]].
Map [[f]] depends on deciding on a convex coordinate space for processing [[P \subset \mathbb{R}^3]] with mapping [[p : C \to P \text{ & } p^{-1} : P \to C]] such that [[p^{-1}(p(x)) = x]]; the original paper uses Oklab for this, described in A perceptual color space for image processing, Björn Ottosson, 2020, which appears to be best-in-class due to its favourable properties for image processing. This gives [[P = [0, 1] \times [\frac{-1}{2}, \frac{1}{2}] \times [\frac{-1}{2}, \frac{1}{2}]]] and
Oklab [[p\text{ & }p^{-1}]]
[![ \begin{align} \text{Let}\\ c'&= \frac{c}{255}\\ l &= c' \cdot (+0.4122214708, +0.5363325363, +0.0514459929)\\ m &= c' \cdot (+0.2119034982, +0.6806995451, +0.1073969566)\\ s &= c' \cdot (+0.0883024619, +0.2817188376, +0.6299787005)\\ (l', m', s') &= (\sqrt[3]{l}, \sqrt[3]{m}, \sqrt[3]{s})\\ \text{then}\\ p(c) = ((l', m', s') &\cdot (+0.2104542553, +0.7936177850, -0.0040720468),\\ (l', m', s') &\cdot (+1.9779984951, -2.4285922050, +0.4505937099),\\ (l', m', s') &\cdot (+0.0259040371, +0.7827717662, -0.8086757660))\\ \end{align} ]!] [![ \begin{align} \text{Let}\\ l' &= p \cdot (1, +0.3963377774, +0.2158037573)\\ m' &= p \cdot (1, -0.1055613458, -0.0638541728)\\ s' &= p \cdot (1, -0.0894841775, -1.2914855480)\\ (l, m, s) &= (l'^3, m'^3, s'^3)\\ \color{var(--r)}r\color{initial}' &= (l, m, s) \cdot (+4.0767416621, -3.3077115913, +0.2309699292)\\ \color{var(--g)}g\color{initial}' &= (l, m, s) \cdot (-1.2684380046, +2.6097574011, -0.3413193965)\\ \color{var(--b)}b\color{initial}' &= (l, m, s) \cdot (-0.0041960863, -0.7034186147, +1.7076147010)\\ \text{then}\\ p^{-1}(p) &= (\lfloor 255 \color{var(--r)}r\color{initial}' \rceil, \lfloor 255 \color{var(--g)}g\color{initial}' \rceil, \lfloor 255 \color{var(--b)}b\color{initial}' \rceil)\\ \end{align} ]!]Then [[f]] depends on radius [[r]] (with a functional range of [[[0, \sqrt{3}]]] in Oklab), and deciding on variation [[palette]] or [[*freq]]: [[*freq]] ends up on the center of mass by weighting by how many times it occurs in [[I]], [[palette]] ends up directly at the mean (as-if all colours had the same weight). With this given:
This can be generalised to transparent images ([[C \times {\mkern 1.5mu\overline{\mkern-1.5mu{256}\mkern-1.5mu}\mkern 1.5mu}]]) by replicating the alpha channel directly: [[I_i = (\color{var(--r)}r\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--b)}b\color{initial}) \to O_i = (\color{var(--r)}r\color{initial}', \color{var(--g)}g\color{initial}', \color{var(--b)}b\color{initial}', a)]] where [[(\color{var(--r)}r\color{initial}', \color{var(--g)}g\color{initial}', \color{var(--b)}b\color{initial}') = f((\color{var(--r)}r\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--b)}b\color{initial}))]]. Fully-transparent pixels should be discarded altogether.
Seeing as [[D]] is constant for either variation, it follows trivially that [[q_t = q_{t-1} \Leftrightarrow M_t = M_{t-1}]] ("the point didn't move between iterations" is equivalent to "the same points are within [[r]] as last iteration").
It may be more convenient computationally to consider [[D = p \circ Multiset(I)]] with [[palette]] reducing the multiplicity of each element to 1. God only knows how to notate this.
It is illustrative at this point to draw out a demonstration. To this end, the following results can be observed (enlarged to show texture):



For demonstrative simplicity, the source colours are all sampled from the Oklab plane at l=0.797447133. Due to quantisation unavoidable since [[|P| \gg |C|]] and them not naturally falling on that plane out of [[p]], the intermediate [[q_t]]s aren't on that plane (but remain relatively close), and those have been projected onto it (but this is why the points don't seem to follow a perfect geometric mean in 2D).
{kind=link}
# [[palette, r=0.1: D=p \circ ((\mathrm{CC}_{16}, \mathrm{4E}_{16}, \mathrm{FF}_{16}), (\mathrm{FF}_{16}, \mathrm{2D}_{16}, \mathrm{FF}_{16}), (\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16}))]]



# [[*freq, r=0.1: D=p \circ \begin{pmatrix}(\mathrm{CC}_{16}, \mathrm{4E}_{16}, \mathrm{FF}_{16}) & (\mathrm{FF}_{16}, \mathrm{2D}_{16}, \mathrm{FF}_{16})\\(\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16}) & (\mathrm{FF}_{16}, \mathrm{2C}_{16}, \mathrm{A6}_{16})\end{pmatrix}]]



In both cases [[t]] ends up being 1 for [[f((\mathrm{FF}_{16}, \mathrm{2D}_{16}, \mathrm{FF}_{16}))]] (top-right) and 2 for the others.
A constant [[t]], smaller than would converge, may be used to achieve more-visually-pleasing output,
but does not accomplish the functionality described by the original paper video.
# Base case
A scaffolding for the implementation is obtained trivially by copy-pasting the sdl2 documentation examples, mashing them together hap-hazardly until a basic GUI appears, and then never touching them again unless they're broken. The SDL2 experience is not a good one on a good day, and the QoI that falls out of this is even worse, but whatever.
More importantly, the pixel layout format is somehow even worse and unpredictable
and you will observe some rows' colour data being wrong on odd-sized images because
row-pitch-in-bytes is not always pixel-stride-in-bytes · image-width,
which appears undocumented in the bindings, barely-documented upstream, and the pixel format is a &[u8] and a "go to hell".
Additionally, it's either per-channel bytes or int with channels allocated from LSB,
and the int is in native byte order which makes
RGB24 [[[\color{var(--r)}r\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--b)}b\color{initial}]]] but
RGBA32 either [[[a, \color{var(--b)}b\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--r)}r\color{initial}]]] or [[[\color{var(--r)}r\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--b)}b\color{initial}, a]]] depending on host endianness,
so you need to explicitly pick the opposite:
ABGR32 on little-endian to get [[[\color{var(--r)}r\color{initial}, \color{var(--g)}g\color{initial}, \color{var(--b)}b\color{initial}, a]]] and vice versa.
That's enough on SDL2.
The core insights informing the implementation is that [[f]] does not depend on the pixel position — just its colour — and that [[D]] is constant for a given [[I]]. This means that computing [[O]] can take place in three distinct steps: analysis by computing [[D]], pre-computing [[f]] for each distinct element in [[D]], mapping the pixels directly into [[O]]. The analysis step can happen just once per [[I]], regardless of variant and [[r]] selection.
Since [[|C| = 2^{24}]] (or, equivalently, [[C \equiv {\color{var(--r)}r\color{initial}}{\color{var(--r)}r\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--b)}b\color{initial}}{\color{var(--b)}b\color{initial}}_{16}]]),
and computer memory is many orders of magnitude larger than 16Mi · any-reasonable-primitive-size,
a map from any colour can easily take the form of a look-up table of size 224.
For example, the multiplicity map of [[D]] (frequencies) and the final map [[f]] (outputs)
are of types
[u32; 0xFFFFFF + 1]
and
[[u8; 3]; 0xFFFFFF + 1]
totalling a mere 112MiB.
Extending this methodology to higher colour bit depths may require slower-but-more-memory-conscious collection types
(10-bit colour ([[C = {\mkern 1.5mu\overline{\mkern-1.5mu{1024}\mkern-1.5mu}\mkern 1.5mu}^3]]) would grow them to to 7GiB).
A 32-bit integer for the multiplicity of each colour means that an entire 40962 image would need to be the same colour to overflow,
which isn't a case we care about.
Thus, the analysis step
(with [[p]] as linear_srgb_to_oklab)
[CW gore @ link, initially building in "debug" (underoptimised 🙄) mode made the counting appear to be faster in parallel with atomics —
this is not the case —
this sample has been reduced to the final single-threaded += model, the rest are temporally accurate]:
let frequencies = [0u32; 0xFFFFFF + 1];
for rgb in image.pixel_data.chunks_exact(pixel_stride) {
let (r, g, b) = (rgb[0], rgb[1], rgb[2]);
frequencies[(r << 16) | (g << 8) | (b << 0)] += 1;
}
#[repr(C)]
struct Lab { l: f32, a: f32, b: f32 }
let known_rgbs: Vec<(u32, Lab, u32)> = frequencies.iter()
.enumerate()
.filter(|(_, freq)| freq != 0)
.map(|(rgb, freq)| {
let (r, g, b): (f32, f32, f32) =
((rgb >> 16) & 0xFF, ((rgb >> 8) & 0xFF), ((rgb >> 0) & 0xFF));
let lab = linear_srgb_to_oklab((r / 255, g / 255, b / 255));
(rgb, lab, freq)
})
.collect();
yields in known_rgbs a sequence of work items [[({\color{var(--r)}r\color{initial}}{\color{var(--r)}r\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--b)}b\color{initial}}{\color{var(--b)}b\color{initial}}_{16}, p(I_{\color{var(--r)}r\color{initial},\color{var(--g)}g\color{initial},\color{var(--b)}b\color{initial}}), \text{multiplicity of}\ \color{var(--r)}r\color{initial},\color{var(--g)}g\color{initial},\color{var(--b)}b\color{initial})]].
let radiussy = 0.02;
let mut outputs = [Lab { .. }; 0xFFFFFF + 1];
let radiussy_squared = radiussy * radiussy;
for (rgb, lab, _) in known_rgbs {
let mut center = lab;
loop {
let (newcenter_count, mut newcenter) = known_rgbs.iter()
.filter(|(_, lab, _)| {
let distance_squared = (lab.l - center.l).sqr() + (lab.a - center.a).sqr() + (lab.b - center.b).sqr();
distance_squared <= radiussy_squared
})
.fold((0, Lab { l: 0, a: 0, b: 0 }), |(cnt, acc), (_, lab, freq)| {
#[cfg(palette)]
(cnt + 1,
Lab {
l: acc.l + lab.l,
a: acc.a + lab.a,
b: acc.b + lab.b,
})
#[cfg(mul_freq)]
(cnt + freq,
Lab {
l: acc.l + lab.l * freq,
a: acc.a + lab.a * freq,
b: acc.b + lab.b * freq,
})
});
newcenter.l /= newcenter_count;
newcenter.a /= newcenter_count;
newcenter.b /= newcenter_count;
if newcenter == center {
break;
}
center = newcenter;
}
outputs[rgb] = center;
}
is a very direct implementation of the [[q_t]] search, with [[t]] being the iteration count of the loop (the only and obvious optimisation is not computing the square root). All elements of [[D]] are evaluated every time. The variant is selected at compile-time but could easily be an if, and the outer-most loop parallelises trivially; for the first test image:
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| not parallel | 19.717s | 11.533s | 58.49% |
| 8× parallel | 6.098s | 3.974s | 65.16% |
| (parallel speed-up) | 3.233× | 2.903× | -6.66 p.p. |
the speed-up is less than half of expected, I'd blame this on low memory bandwidth and overall decrodedness of the i7-2600. I'd thought that [[*freq]] converged ~40% faster due to the specific data contained in the test image, which makes direct comparison of the two difficult; henceforth, images annotated d are the "degenerate" versions of their base case, with every colour appearing once, making [[*freq]] equivalent to [[palette]]:
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| not parallel | 9.812s | 6.853s | 69.84% |
| 8× parallel | 2.924s | 2.012s | 68.79% |
| (parallel speed-up) | 3.355× | 3.406× | -1.05 p.p. |
One would expect (more floating-point operations executed, more data loaded) [[*freq]] to be, at best, the same speed as [[palette]], but the optimiser actually makes the [[palette]] implementation 30% worse. Science cannot explain this.
And the output mapping step (with [[p^{-1}]] as oklab_to_linear_srgb):
for (to_rgb, from_rgb) in image_processed.pixel_data.chunks_exact_mut(pixel_stride)
.zip(image .pixel_data.chunks_exact (pixel_stride)) {
let (r, g, b) = (from_rgb[0], from_rgb[1], from_rgb[2]);
let rgb = oklab_to_linear_srgb(outputs[(r << 16) | (g << 8) | (b << 0)]);
to_rgb[0] = (rgb.r * 255).round();
to_rgb[1] = (rgb.g * 255).round();
to_rgb[2] = (rgb.b * 255).round();
}
This, well, works. It's not "fast" but since practically every Minecraft texture has <100 distinct colours I expect the original author to have finished here since at that scale each iteration is basically instant. But since each [[f(c)]] inspects each distinct element of [[D]] [[t]] times, the total complexity is [[\propto (\overline{Set(D)})^2 t_{avg}]] which for more colourful images this simply won't do.


[[\Sigma t = 440133]]

[[\Sigma t = 358543]]
To wit: the unified Minecraft Alpha v1.2.2 block texture atlas has 400 distinct colours and converges in [[\Sigma t = 423378]]/[[\Sigma t = 664403]], respectively with the same settings, in <1ms.
Output mapping is a little sub-optimal for large images, since it re-computes [[p']] for every pixel every time (a large (21602) image takes 176ms to map). By in situ applying [[p']] to turn [Lab; 0xFFFFFF + 1] into [[u8; 3 + padding]; 0xFFFFFF + 1]:
type RgbStuffedInLab = [u8; mem::size_of::<Lab>()];
for (rgb, _, _) in known_rgbs {
let result = oklab_to_linear_srgb(outputs[rgb]);
let to_rgb: &mut RgbStuffedInLab = unsafe { mem::transmute(&mut outputs[rgb]) };
to_rgb[0] = (result.r * 255).round();
to_rgb[1] = (result.g * 255).round();
to_rgb[2] = (result.b * 255).round();
}
let outputs_rgb: &[RgbStuffedInLab; 0xFFFFFF + 1] = unsafe { mem::transmute(&outputs) };
for (to_rgb, from_rgb) in image_processed.pixel_data.chunks_exact_mut(pixel_stride)
.zip(image .pixel_data.chunks_exact(pixel_stride)) {
let (r, g, b) = (from_rgb[0], from_rgb[1], from_rgb[2]);
to_rgb.copy_from_slice(outputs_rgb[(r << 16) | (g << 8) | (b << 0)]);
});
This drops to 16ms, and correspondingly less on smaller images — immaterial on the scale of seconds.
The data flow, at this point, can be analysed trivially as

This allows one, like goodyear, to put the
# rubber to the road
When looking for bindings, I was looking for something strongly-typed and with reasonable documentation. To that end, I evaluated wgpu — first by fixing the broken links to the examples, then by getting whiplash from the "Learn" document which simultanously covers "what is Rust", "this implements the WebGPU API to look like the Vulkan API and translates Some how to Some back-end", "how to create a Rust crate", "you must have a window handle and use our logger", and "use this specific version of an intermediate dependency otherwise it all explodes". No googleable compute shaders seem to be extant for it, either.
After a few less remarkable ones, I'd settled on vulkanalia because, in reverse order of import:
- he he kanalia,
- it appeared to competently implement both a direct Vulkan binding and a 10% more structured and 40% less verbose "builder" scheme that supposedly avoided dangling references (in retrospect, it's done that quite well), thus allowing easy adaptation of other Vulkan posts,
- it has a direct port — Vulkan Tutorial (Rust), Kyle Mayes, trans., Alexander Overvoorde, &a. — of the upstream Vulkan tutorial, which is basically best-in-class.
Admittedly, the tutorial also wants to make a window and render but this can be strategically ignored, and which bits are strictly for windowing is relatively obvious. The port doesn't include the Compute Shader sexion, but, counter to the rest of the text, I've found it to be quite poor. To this end, A Simple Vulkan Compute Example in C++, Baked Bits, 2021 performs quite well, working out from "you have a functioning vulkan context" holistically through to "you are executing the shader".
As part of the Example, a shader compilation method is specified with dxc, which doesn't appear to be distributed by any-one (defined here-in as "Debian or MSYS2"). The standard and universal solution appears to be glslc, which, contranomenclaturally, actually compiles GLSL and HLSL, and also has a C-style preprocessor. Not a great one, but, better yet, a good-enough one. This allows a simple build.rs:
fn main() {
let processes = vec![];
for f in fs::read_dir("src").map(|r| r.path()).filter(|p| p.extension() == "hlsl") {
println!("cargo::rerun-if-changed={}", f.display());
proceses.push(std::process::Command::new("glslc")
.args(&["-fshader-stage=compute", "-g", "-O"])
.args(&["-o", Path::new(&env::var_os("OUT_DIR")).join(f.file_name()).with_extension("spv")])
.args(&[f])
.spawn());
}
for proc in processes
proc.wait().exit_ok().unwrap();
}
}
which is equivalent to a glslc -fshader-stage=compute -g -O -o $(OUT_DIR)/$(subst .hlsl,.spv,$@) $<
rule for every file matching src/*.hlsl.
-fshader-stage could've been substituted by replacing .hlsl with .comp,
and thankfully, in contrast to the devilish DXC cmdline, -O and -g are like in normal compilers
(though, with the "targeting IR" compilation model, -g has an apt side-effect of including the full source
and per-instruction line number annotations in the shader binary!
this is convenient when you need to figure out if the optimiser is fucking you, but irrelevant most of the time).
Overall, the tooling is pretty mature, just the subject matter largely hateful.
What is relevant but not immediately obvious is that DXC
requires
the entry point to be specified explicitly (as Main in the Example),
but glslc defaults to main,
and this needs to agree with both the source and
vk::PipelineShaderStage
More confusingly,
vk::ShaderModuleCreateInfo::code and ::code_size
takes, separately, an array of u32s and a length of that array in u32s (not bytes!).
This array must be aligned, even on amd64 where misalignment doesn't usually trap.
As an added bonus from a testing perspective, you do just get a SIGBUS, but not on Win32, because the linker always aligns the shader (well, did for me).
Nothing an
include_typed!(u32, ".../shader.spv")
macro can't fix, but the Cargo compilation model and the way the implementation works being "magic" did not help.
Some would say that Rust is not any better than C++ at this
(but, well, I would be able to slap a [[alignas(std::uint32_t)]] on it there, so this is actually kind of an L).
The terminology is a little sneaky as well: what Vulkan calls a "pipeline" is actually just a shader in human language, and a "command buffer" is a pipeline. One may also that think "command buffers"… buffer commands. They don't, you can only put one pipeline (though an arbitrarily complex one!) in there at a time. Most-everything else scans relatively sanely.
I had been a little slow on the up-take on validation layers
(largely owing to the fact that the MSYS2 package didn't make them work and I didn't really want to fuck my whole shit up by installing something random;
this is of course not an issue for users of normal distributions).
My concern was misplaced: the upstream LunarG Vulkan SDK Just Worked and didn't interfere with anything else.
The validation layers are, frankly, a marvel of a dynamic analysis suite (and they let you have printf-from-shader).
What's a bit less of a wonder is the non-printf debugging sitch.
If you're rendering you use RenderDoc, but that doesn't capture compute pipelines.
Well it claims it does, experimentally, but I haven't managed to have that happen.
Vendor-specific tooling — in my case the Radeon Developer Panel — is presumably the only option,
but I haven't gotten it to work on my computer and with my GPU and with Vulkan.
Some part of the fire triangle's always failed to materialise for me.
The Example's seemingly-only fault is that it does not use memory barriers, and it's true that it seems to work fine without them, but more complex programs (however they're defined, this one definitely fits!) do actually need them, even in coherent memory and if no concurrent access occurs and everything is fence-synchronised. These have been elided from the samples here because they're pretty verbose.
With this pre-amble/summary in mind and no fan-fare, Example's shader works. Since known_rgbs could have anywhere [[\in [1, 2^{24}]]] elements (but is very unlikely to have actually that many), a way to bump the buffers is nice.
In a few simple steps it can be expanded and adapted to implement the pre-computation step:
struct params_t {
uint known_rgbs_len;
float radiussy;
uint iter_limit;
};
struct known_rgbs_pack {
float3 lab;
uint rgb;
};
[[vk::binding(0)]] RWStructuredBuffer<float3> outputs;
[[vk::binding(1)]] StructuredBuffer<params_t> params;
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle;
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const float radiussy = params[0].radiussy;
const uint iter_limit = params[0].iter_limit;
const uint id = DTid.x;
known_rgbs_pack this = known_rgbs_bundle[id];
float3 center = this.lab;
for(uint iter = 0; iter < iter_limit; ++iter) {
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint i = 0; i < known_rgbs_len; ++i) {
float3 lab = known_rgbs_bundle[i].lab;
if(length(lab - center) <= radiussy) {
newcenter_count += 1;
newcenter += lab;
}
}
newcenter /= newcenter_count;
bool same = newcenter == center;
if(same)
break;
center = newcenter;
}
outputs[this.rgb] = center;
}
As driven by (initially the nomenclature was derived from posterisation instead of mean-shift clustering; this is be corrected later):
static SHADER_DATA: &[u32] = include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise.spv"));
#[repr(C)]
struct ParamsT {
known_rgbs_len: u32,
radiussy: f32,
iter_limit: u32,
}
#[repr(C)]
struct KnownRgbsPack {
lab: Lab,
rgb: u32,
}
pub struct PosteriseGpu {
// ...
device: vulkanalia::Device,
compute_pipeline: vulkanalia::Pipeline,
memory_type_index: u32, // HOST_VISIBLE & HOST_COHERENT
buffer_outputs: BufferBundle, // [[vk::binding(0)]] SB<float3> outputs;
buffer_params: BufferBundle, // [[vk::binding(1)]] SB<params_t> params;
buffer_known_rgbs_bundle: BufferBundle, // [[vk::binding(2)]] SB<known_rgbs_pack> known_rgbs_bundle;
buffer_outputs_map: &'static mut [[f32; 4]; 0xFFFFFF + 1],
buffer_params_map: &'static mut ParamsT,
}
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
let vk_shader_module = vk_device.create_shader_module(&vk::ShaderModuleCreateInfo::builder()
.code_size(SHADER_DATA.len() * 4).code(SHADER_DATA), None);
dev.compute_pipeline = {
let pipeline_shader_create_info = vk::PipelineShaderStageCreateInfo::builder()
.stage(vk::ShaderStageFlags::COMPUTE)
.module(vk_shader_module)
.name(b"main\0");
let compute_pipeline_create_info = vk::ComputePipelineCreateInfo::builder()
.stage(pipeline_shader_create_info) /*...*/;
vk_device.create_compute_pipelines(vk_pipeline_cache, &[compute_pipeline_create_info], None).0.swap_remove(0)
};
ret.buffer_outputs = ret.ensure_buffer(BufferBundle{}, mem::size_of::<[[f32; 4]; 0xFFFFFF + 1]>());
ret.buffer_outputs_map = &mut *ret.device.map_memory(ret.buffer_outputs);
ret.buffer_params = ret.ensure_buffer(BufferBundle{}, mem::size_of::<ParamsT>());
ret.buffer_params_map = &mut *ret.device.map_memory(ret.buffer_params);
ret
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, outputs: &mut [Lab; 0xFFFFFF + 1]) {
self.buffer_known_rgbs_bundle = self.ensure_buffer(self.buffer_known_rgbs_bundle, known_rgbs.len() * mem::size_of::<KnownRgbsPack>());
assert!(mem::size_of::<KnownRgbsPack>() == 4 * 4);
*self.buffer_params_map = ParamsT {
known_rgbs_len: known_rgbs.len(),
radiussy: radiussy,
iter_limit: 0xFFFFFFFF,
};
let buffer_known_rgbs_bundle_map = self.device.map_memory(self.buffer_known_rgbs_bundle);
let known_rgbs_bundle: &mut [KnownRgbsPack] = slice::from_raw_parts_mut(buffer_known_rgbs_bundle_map, known_rgbs.len());
for ((rgb, lab, _), dest_lab) in known_rgbs.iter().zip(known_rgbs_bundle.iter_mut()) {
dest_lab = KnownRgbsPack {
rgb: rgb,
lab: lab,
};
}
self.device.unmap_memory(self.buffer_known_rgbs_bundle.buffer_memory);
self.descriptor_set = self.device.update_descriptor_sets(vk::WriteDescriptorSet{[self.buffer_outputs, self.buffer_params, self.buffer_known_rgbs_bundle]});
self.device.begin_command_buffer(self.cmd_buffer);
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline);
self.device.cmd_bind_descriptor_sets(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.pipeline_layout, 0, &[self.descriptor_set], &[]);
// cmd_pipeline_barrier(HOST -> COMPUTE_SHADER: (self.buffer_params, self.buffer_known_rgbs_bundle): HOST_WRITE -> SHADER_READ)
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len() /* x */, 1 /* y */, 1 /* z */);
// cmd_pipeline_barrier(COMPUTE_SHADER -> HOST: self.buffer_outputs: SHADER_WRITE -> HOST_READ)
self.device.end_command_buffer(self.cmd_buffer);
self.device.reset_fences(&[self.fence]).unwrap();
self.device.queue_submit(self.compute_queue, &[vk::SubmitInfo::builder().command_buffers(&[self.cmd_buffer])], self.fence);
self.device.wait_for_fences(&[self.fence], true, u64::MAX).unwrap();
for (rgb, _, _) in known_rgbs {
outputs[rgb].l = self.buffer_outputs_map[rgb][0];
outputs[rgb].a = self.buffer_outputs_map[rgb][1];
outputs[rgb].b = self.buffer_outputs_map[rgb][2];
}
}
The Example mapped and unmapped the buffers every time at point of use, which seems to have no up-side:
params and outputs are always mapped.
It uses [[\text{numthreads} = (1, 1, 1), \text{dispatch}(k, 1, 1)]], which is fine for its application. On expert advice for "why is this so damn slow still", I'd naively upgraded to [[\text{numthreads} = (64, 1, 1), \text{dispatch}(k, 1, 1)]] (where [[k ={\ }]]known_rgbs.len()), which exposes a glaring bug: the "threads" dispatched in each dimension are [[\prod_{x \in \text{numthreads} \odot \text{dispatch}} [0, x )\ (\text{all in}\ \mathbb{Z})]], so, in this case, [[[0, 64n ) \times [0, 1 ) \times [0, 1 )]] instead of the desired [[[0, \mathbin{\approx}k ) \times [0, 1 )^2]] (which took even longer, hence why iter_limit to avoid spinning forever in uninitialised memory out of bounds).
I've only just now realised Vulkan Tutorial, Compute Shader, Alexander Overvoorde &a. describes this (hint: it's not Running compute commands, Dispatch! it's actually Compute Space!) and I don't think it does a great job of it: the description is incredibly wordy and disconnected from where the other "256" is, defines only the edge-case when [[k \bmod 64 = 0]], and the shader is not prepared for the ignore-if-past-the-end situation. Also, the way this maps to the variables/globals is not referenced at all.
I've found
Direct3D / HLSL / numthreads, Microsoft Learn
to surprisingly be the best here, and the explanatory figure, while more schizo, actually more informative.
The correct implementation is
[[\text{numthreads} = (64, 1, 1), \text{dispatch}(\lceil\frac{k}{64}\rceil, 1, 1)]]
which yields
[[[1, k+\varepsilon ) \times [0, 1 )^2]]
where
[[\varepsilon \in [0, 64 )]].
The former can be conveniently
expressed builtinly as known_rgbs.len().div_ceil(64)
and the latter rejected with
const uint id = DTid.x;
if(id >= current_rgbs_len)
return;
this appears canonical, but honestly I haven't found a model would satisfactorily define the appx. 10 different views into the job dispatch matrix. (Personal failing.)
Why 64 specifically? I measured and everything else is worse. Something to do with compute unit sizes or whatever? Unclear.
That bit about the Example having one fault? Not true actually. It doesn't mention fence resetting. If you're like me, god forbid, and don't intently read through 60% of the Vulkan Tutorial (since you're actually reading Vulkan Tutorial (Rust) which only mentions it in Rendering and presentation), and be directed to consume Vulkan Guide / Using Vulkan / Synchronization / Synchronization Examples in its entirety; it's instructive and honestly the best piece of documentation mentioned so far, but still doesn't mention that you indeed have missed the need for the reset_fences() call and this was worth two hours.
The fence overall is unnecessary if not scheduling multiple shaders at once, and can be replaced with a queue_wait_idle() call, but if you're waiting on it and it's already completed once then it'll just not block again.
One may note the mismatch of outputs being SB<float3> but then also [[f32; 4]; …], as well as params also being in a SB even though there's only one of them, ever. This is due to a confluence of two HLSL oddities:
- arrays have either a 4-byte or a 16-byte alignment
- globals not part of a SB are collected and encapsulated into a single global you can't control
thus, SB<float3> is actually SB<(float3, 4 unused bytes),
which also means that known_rgbs_bundle is packed optimally.
Arrays whose elements are 1/2 scalars (4/8 bytes) are 4-byte-aligned.
Larger arrays are 16-byte-aligned.
Structures are, functionally, arrays of their elements as well:
struct { float3, float3 } has a padding scalar between them, which you can use if you want
(this explains the goofy lay-out of params_t later).
This, AIUI, corresponds to GLSL std430/std140 layouts,
except determined automagically and you have to validate the layout yourself sometimes. Fun!
This is a direct port of the CPU implementation above (sans square distance optimisation), and only of [[palette]].
The hawk-tuah'deyed reader has spotted that center is redundant,
and so is bool same, except the assignment from bool3 acts like an all()
(every operator is piece-wise, and == is no exception;
some-how for other types this is obvious to me, but for booln it's consistently failed to internalise.
Personal failing 2).
With the dispatching fixed
(all times measured hence include copying buffer_outputs_map to outputs):
| (colours) | 16'755, [[palette]] | ±σ |
|---|---|---|
| 5700 XT | 132.734ms | 464µs |
| (speed-up vs 8×) | 40.782× |
The memory lay-out is largely replicated directly as well (this is not fast or good, but it is drop-in):
outputs is fixed-size since it's a scatter output, but
known_rgbs_bundle is only as big as known_rgbs (distinct colours in [[I]]),
so it can be bumped if the new size required is larger than the last size.
Since
reallocating means "free, allocate",
it can't be mapped for any longer.
At least we get the real allocated size as SOP, so if there's any rounding up (there is), we are aware and can skip extraneous allocations.
This could, in principle, function as Just A Faster Implementation,
but my Win32 amdgpu-equivalent driver kills the shader and returns TIMEOUT if it takes longer than ~8s
(which is honestly better than any alternative
and we see how many values were fully-computed since outputs was updated by the threads that did manage to finish).
By observing that length(v) [[= \sqrt{v_x^2 + v_y^2 + v_z^2} = \sqrt{v_xv_x + v_yv_y + v_zv_z} = \sqrt{v \cdot v} =]] sqrt(dot(v, v))
(though it actually lowers directly into OpExtInst %float (OpExtInstImport "GLSL.std.450") Length %v
instead of OpExtInst %float %… Sqrt %(OpDot %float %v %v)),
the obvious optimisation
can be restored
(with dispatching fixed likewise):
struct params_t {
uint known_rgbs_len;
float radiussy_squared;
uint iter_limit;
};
// ...
float3 tmp = lab - center;
if(dot(tmp, tmp) <= radiussy_squared) {
| (colours) | 16'755, [[palette]] |
|---|---|
| 5700 XT | 128.871ms |
| (speed-up vs previous) | 2.91% |
Now all it takes for the
# base-line
port is implementing [[*freq]].
glslc's preprocessor implementation allows a de-duplicated implementation, much like the #[cfg]s prior;
posterise_kernel.hlsl.inc:
struct params_t {
uint known_rgbs_len;
float radiussy_squared;
int iter_limit;
};
struct known_rgbs_pack {
float3 lab;
uint rgb;
};
[[vk::binding(0)]] RWStructuredBuffer<float3> outputs;
[[vk::binding(1)]] StructuredBuffer<params_t> params;
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle;
KNOWN_RGBS_FREQS
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const float radiussy_squared = params[0].radiussy_squared;
const uint iter_limit = params[0].iter_limit;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
known_rgbs_pack this = known_rgbs_bundle[id];
float3 center = this.lab;
for(int iter = 0; iter != iter_limit; ++iter) {
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint i = 0; i < known_rgbs_len; ++i) {
float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
if(dot(tmp, tmp) <= radiussy_squared) {
FREQ_LOAD
newcenter_count += FREQ;
newcenter += lab TIMES_FREQ;
}
}
newcenter /= newcenter_count;
bool same = newcenter == center;
if(same)
break;
center = newcenter;
}
outputs[this.rgb] = center;
}
#define KNOWN_RGBS_FREQS
#define FREQ_LOAD
#define FREQ 1
#define TIMES_FREQ
#include "posterise_kernel.hlsl.inc"
#define KNOWN_RGBS_FREQS [[vk::binding(3)]] StructuredBuffer<uint4> known_rgbs_freqs;
#define FREQ_LOAD uint freq = known_rgbs_freqs[i / 4][i % 4];
#define FREQ freq
#define TIMES_FREQ * freq
#include "posterise_kernel.hlsl.inc"
These expand to
for(uint i = 0; i < known_rgbs_len; ++i) {
float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
if(dot(tmp, tmp) <= radiussy_squared) {
newcenter_count += 1;
newcenter += lab;
}
}
and
for(uint i = 0; i < known_rgbs_len; ++i) {
float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
if(dot(tmp, tmp) <= radiussy_squared) {
uint freq = known_rgbs_freqs[i / 4][i % 4];
newcenter_count += freq;
newcenter += lab * freq;
}
}
respectively.
known_rgbs_freqs being an array of uint4s is unfortunate and unnecessary, but the minutiae of automagic layout bull shit were not obvious to me at the time. This is functionally-equivalent to an array of uints being indexed by i directly.
By storing the population data separately with the same indexing, the optimal zero-padding layout is preserved
(adding it into a known_rgbs_pack would mean { (float3, uint), (uint, 3 4-byte padding primitives) }),
and the population can be only loaded when necessary, which minimises performance impact.
Since the uniforms
([[vk::binding]]-tagged StructuredBuffers;
it's unclear why some literature calls them "uniforms", Vulkan calls them bindings
or bound descriptor sets
and the like universally AFAICT)
use a global indexing system defined by the host,
any shader can use any subset of them.
This will be (ab)used extensively, and every shader will be given all of them,
but will pick out and RW-mark only the ones it cares about.
Nominally, Vulkan only has 4 bindings in baseline,
but you just ask for however-many you need
and abort; it may be nice to
check before-hand,
but the value is marginal since all GPUs mentioned heretofore support 32.
The driver
requires minimal modification,
functionally duplicating most of it
(this can
be
instrumented
well
with [Т; N].map();
suffers a bit with Rust's lack of C-style auto-incrementing self-referential enums. ah well):
pub struct PosteriseGpu {
// ...
device: vulkanalia::Device,
compute_pipeline: vulkanalia::Pipeline, // posterise.hlsl
compute_pipeline_mul: vulkanalia::Pipeline, // posterise_mul.hlsl
memory_type_index: u32, // HOST_VISIBLE & HOST_COHERENT
buffer_outputs: BufferBundle, // [[vk::binding(0)]] SB<float3> outputs;
buffer_params: BufferBundle, // [[vk::binding(1)]] SB<params_t> params;
buffer_known_rgbs_bundle: BufferBundle, // [[vk::binding(2)]] SB<known_rgbs_pack> known_rgbs_bundle;
buffer_known_rgbs_freqs: BufferBundle, // [[vk::binding(3)]] SB<uint4> known_rgbs_freqs;
buffer_outputs_map: &'static mut [[f32; 4]; 0xFFFFFF + 1],
buffer_params_map: &'static mut ParamsT,
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
self.buffer_known_rgbs_bundle = self.ensure_buffer(self.buffer_known_rgbs_bundle, known_rgbs.len() * mem::size_of::<KnownRgbsPack>());
assert!(mem::size_of::<KnownRgbsPack>() == 4 * 4);
if freq_weighting {
self.buffer_known_rgbs_freqs = self.ensure_buffer(self.buffer_known_rgbs_freqs, known_rgbs.len().div_ceil(4) * mem::size_of::<[f32; 4]>());
}
self.buffer_params_map = ParamsT {
known_rgbs_len: known_rgbs.len(),
radiussy: radiussy,
iter_limit: -1,
};
let buffer_known_rgbs_bundle_map = self.device.map_memory(self.buffer_known_rgbs_bundle);
let known_rgbs_bundle: &mut [KnownRgbsPack] = slice::from_raw_parts_mut(buffer_known_rgbs_bundle_map, known_rgbs.len());
for ((rgb, lab, _), dest_lab) in known_rgbs.iter().zip(known_rgbs_bundle.iter_mut()) {
dest_lab = KnownRgbsPack {
rgb: rgb,
lab: lab,
};
}
self.device.unmap_memory(self.buffer_known_rgbs_bundle.buffer_memory);
if freq_weighting {
let buffer_known_rgbs_freqs_map = self.device.map_memory(self.buffer_known_rgbs_freqs);
let known_rgbs_freqs: &mut [[u32; 4]] = slice::from_raw_parts_mut(buffer_known_rgbs_freqs_map, known_rgbs.len().div_ceil(4));
for ((_, _, freq), dest_freq) in known_rgbs.iter().zip(known_rgbs_freqs.iter_mut().flatten()) {
dest_freq = freq;
}
self.device.unmap_memory(self.buffer_known_rgbs_freqs.buffer_memory);
}
self.descriptor_set = self.device.update_descriptor_sets(vk::WriteDescriptorSet{[/* … */, self.buffer_known_rgbs_freqs]});
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE,
if freq_weighting { self.compute_pipeline_mul } else { self.compute_pipeline });
// cmd_pipeline_barrier(HOST -> COMPUTE_SHADER: also self.buffer_known_rgbs_freqs: HOST_WRITE -> SHADER_READ)
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len().div_ceil(64) /* x */, 1 /* y */, 1 /* z */);
self.device.queue_submit(self.compute_queue, &[vk::SubmitInfo::builder().command_buffers(&[self.cmd_buffer])], self.fence);
self.device.wait_for_fences(&[self.fence], true, u64::MAX).unwrap();
for (rgb, _, _) in known_rgbs {
outputs[rgb].l = self.buffer_outputs_map[rgb][0];
outputs[rgb].a = self.buffer_outputs_map[rgb][1];
outputs[rgb].b = self.buffer_outputs_map[rgb][2];
}
}
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 128.854ms | 118.864ms | 92.25% |
| (speed-up vs previous) | <0.015% | ||
| (speed-up vs 8×) | 42.010× | 33.047× | -27.09 p.p. |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 130.972ms | 151.862ms | 115.95% |
| (speed-up vs 8×) | 42.450× | 28.986× | -47.16 p.p. |
[[*freq]] being 16% slower than [[palette]] finally matches the expectation based on complexity; [[palette]] hasn't changed, and it's dead-on the same.
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 129.33ms | 6.606s | [time-out; ~106/155] | 1.262ms/245.740ms |
| 5700 XT, [[*freq]] | 121.11ms | 4.357s | [time-out; ~145/152] | 3.066ms/439.297ms |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 1.456s | [time-out; 0/220] | [time-out; ~225/6505] | 54.549ms |
| 5700 XT, [[*freq]] | 373.43ms | [time-out; ~79/132] | [time-out; ~1627/5075] | 42.771ms |
Computation of cells labelled time-outwas terminated by the driver after like 8-11s; progress corresponds to how many distinct output colours ([[\overline{Set(O)}]]) were produced vs. a correct implementation; this is a very vague proxy measured for a very vague amount of time. | ||||
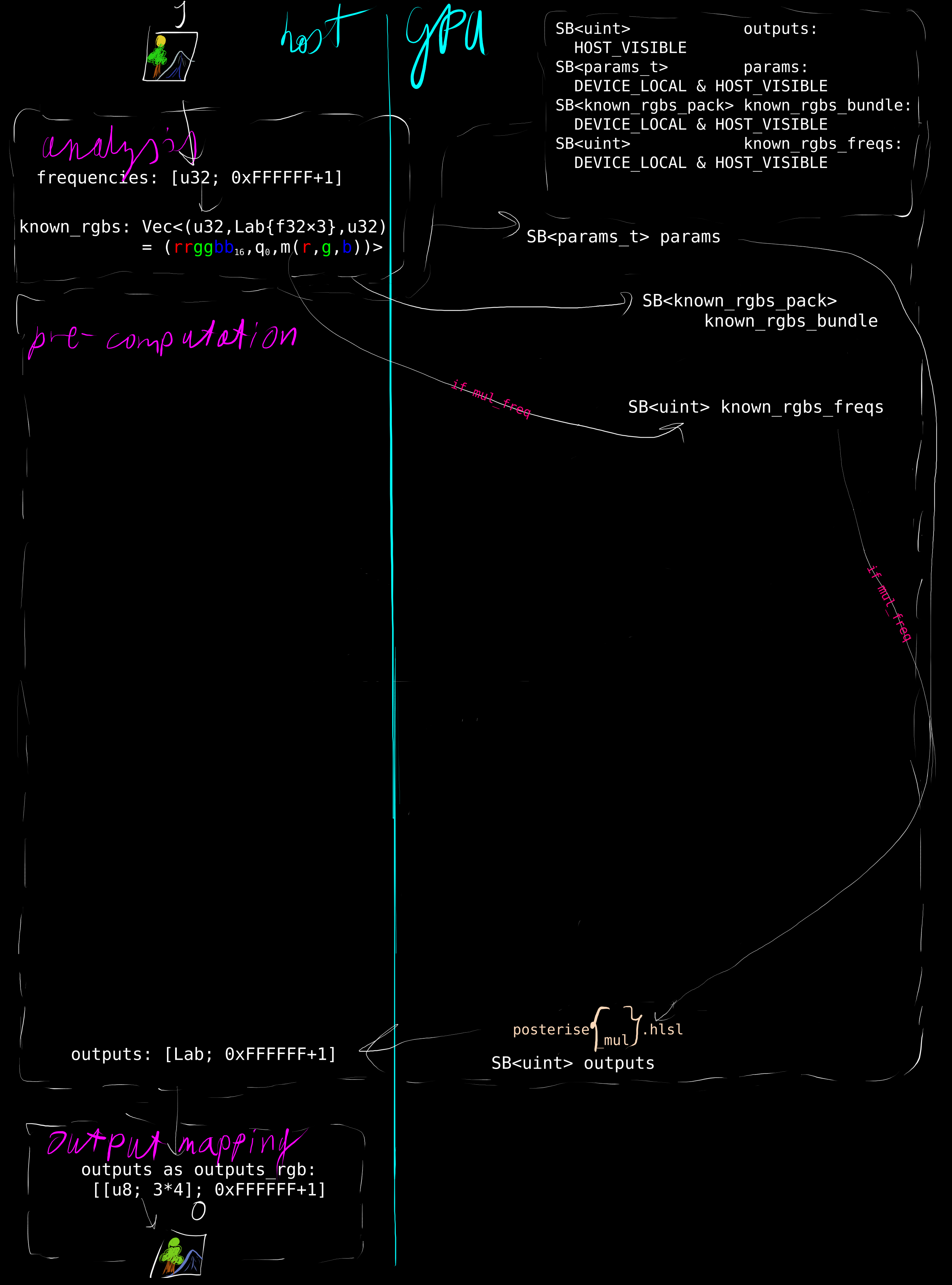
So far, all buffers have been allocated in HOST_VISIBLE & HOST_COHERENT memory like in the Example, which was basically fine, but proper usage of
# memory types
is required to achieve best performance with the widest device support matrix.
vk_instance.
yields a list of memory types, already sorted by preference.
Thus, "a [[Q]] memory" is commonly taken to mean "the first memory type that satisfies predicate [[Q]]",
and since memory features are typified by bitmask,
the predicate is mostly expressed as a conjunction of desired bits.
Listing the memory types on the GPUs in question
yields:
| 7920MiB | DEVICE_LOCAL |
| 7909MiB | HOST_VISIBLE | HOST_COHERENT |
| 256MiB | DEVICE_LOCAL | HOST_VISIBLE | HOST_COHERENT |
| 7909MiB | HOST_VISIBLE | HOST_COHERENT | HOST_CACHED |
| (these repeat with | DEVICE_COHERENT_AMD | DEVICE_UNCACHED_AMD set) | |
| 4080MiB | DEVICE_LOCAL |
| 4080MiB | DEVICE_LOCAL |
| 32110MiB | HOST_VISIBLE | HOST_COHERENT |
| 4080MiB | DEVICE_LOCAL | HOST_VISIBLE | HOST_COHERENT |
| 4080MiB | DEVICE_LOCAL | HOST_VISIBLE | HOST_COHERENT |
| 32110MiB | HOST_VISIBLE | HOST_COHERENT | HOST_CACHED |
| 32110MiB | HOST_VISIBLE | HOST_COHERENT | HOST_CACHED |
| (these repeat, after uniquification, with | DEVICE_COHERENT_AMD | DEVICE_UNCACHED_AMD set) | |
| 32007MiB | DEVICE_LOCAL |
| 32007MiB | DEVICE_LOCAL | HOST_VISIBLE | HOST_COHERENT |
| 32007MiB | DEVICE_LOCAL | HOST_VISIBLE | HOST_COHERENT | HOST_CACHED |
| 32007MiB | DEVICE_LOCAL | PROTECTED |
| (these, minus the | PROTECTED one, repeat verbatim) | |
For the purposes of writing the shaders, I was targeting the 5700 XT in my desktop; conveniently, this is also the most restrictive device. It appears that GPUs can only see up to 32GiB of host memory (or, indeed, memory at all), regardless of how much is actually attached (I can come up with excuses for the discrete 6500 XT, but the Intel iGPU? no clue). It's likewise unclear to me why the 6500 XT doubles up on some memory types (it's not the heap flags, those are also the same (DEVICE_LOCAL and empty, resp.)). Doesn't really matter or affect funxionality in any way, it's just a little goofy.
All three input buffers are accessed constantly (and written directly by the host), so they need to be in DEVICE_LOCAL & HOST_VISIBLE & HOST_COHERENT memory (taking up [[\operatorname{sizeof}(\texttt{params}) + k (\operatorname{sizeof}(\texttt{}\text{(}\texttt{float3}\text{, }\texttt{uint}\text{)}) + \operatorname{sizeof}(\texttt{uint}))]], so 20B per unique colour). This is a precious resource, so outputs can't fit here ([[2^{24} \operatorname{sizeof}(\texttt{float4})]] is the whole [[256\text{MiB}]]!), but from the perspective of the GPU, outputs is write-once write-only, and the last iteration of [[f]], functionally, uploads the result, so it doesn't need to be DEVICE_LOCAL anyway, since the latency or speed don't matter.
Fall-backs are implemented from more specific to more generic memory types (DEVICE_LOCAL & HOST_VISIBLE & HOST_COHERENT → HOST_VISIBLE & HOST_COHERENT), but I haven't encountered a device where this fall-back is taken. Using these improved memory types yields
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 125.566ms | 116.503ms | 92.78% |
| (speed-up vs base-line) | 3.288ms | 2.361ms | |
| (speed-up vs base-line) | 2.55% | 1.99% | |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 127.674ms | 148.930ms | 116.65% |
| (speed-up vs base-line) | 3.298ms | 2.931ms | |
| (speed-up vs base-line) | 2.52% | 1.93% |
# who up branchin they execution
If there's half of one potential thing I know about the GPU execution model, it's that branches are either expensive or not real or some mixture of the two. [[palette]]'s branch can be flattened out; so can [[*freq]]'s (but shouldn't, it's worse), with a trivial change to the common kernel:
#define KNOWN_RGBS_FREQS
#define BRANCHLESS_ADD 1
#define FREQ_LOAD
#define FREQ matched
#include "posterise_kernel.hlsl.inc"
#define KNOWN_RGBS_FREQS [[vk::binding(3)]] StructuredBuffer<uint4> known_rgbs_freqs; // DEVICE_LOCAL & HOST_VISIBLE & HOST_COHERENT
#define BRANCHLESS_ADD 0
#define FREQ_LOAD uint freq = known_rgbs_freqs[i / 4][i % 4];
#define FREQ freq
#include "posterise_kernel.hlsl.inc"
for(uint i = 0; i < known_rgbs_len; ++i) {
float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
#if !BRANCHLESS_ADD
if(matched)
#endif
{
FREQ_LOAD
newcenter_count += FREQ;
newcenter += FREQ * lab;
}
}
which expand to, effectively,
float3 tmp = lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
newcenter_count += matched;
newcenter += matched * lab;
float3 tmp = lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
if(matched) {
uint freq = known_rgbs_freqs[i / 4][i % 4];
newcenter_count += freq;
newcenter += freq * lab;
}
yielding
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 123.416ms | 113.429ms | 91.91% |
| (speed-up vs previous) | 1.71% | 2.64% | 0.87 p.p. |
| (speed-up vs base-line) | 4.22% | 4.57% | 0.34 p.p. |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 123.776ms | 147.078ms | 118.83% |
| (speed-up vs previous) | 3.05% | 1.24% | -2.18 p.p. |
| (speed-up vs base-line) | 5.49% | 3.15% | -2.89 p.p. |
For reference, "worse" means, giving [[*freq]] BRANCHLESS_ADD = 1 and FREQ = matched * freq:
| (colours) | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|---|
| 5700 XT | 116.641ms | 94.51% | 148.654ms | 101.07% |
| (speed-up vs not that) | -2.83% | 2.60 p.p. | -1.07% | -17.75 p.p. |
# Hitting the griddy? In this economy?
Any particle system, which this is, is improved by spatially partitioning constituent particles, and iterating only those whose partitions fall within the radius of influence. This applies basically-straight-forwardly to this problem, except that since the underlying set of [[Multiset(D)]] is constant, the elements of [[D]] can be assigned to constant cells (or, equivalently but more importantly, cells can be said to contain a constant subset of [[D]], where no two cells share any elements and the union of all cells is [[D]]) a priori, but each iteration of [[q_t]] moves around, so the cell it's found in will differ.
For optimal (well, "in any way meaningful") occupancy, we must additionally observe a nigh-universal factoid about the shape of the data:
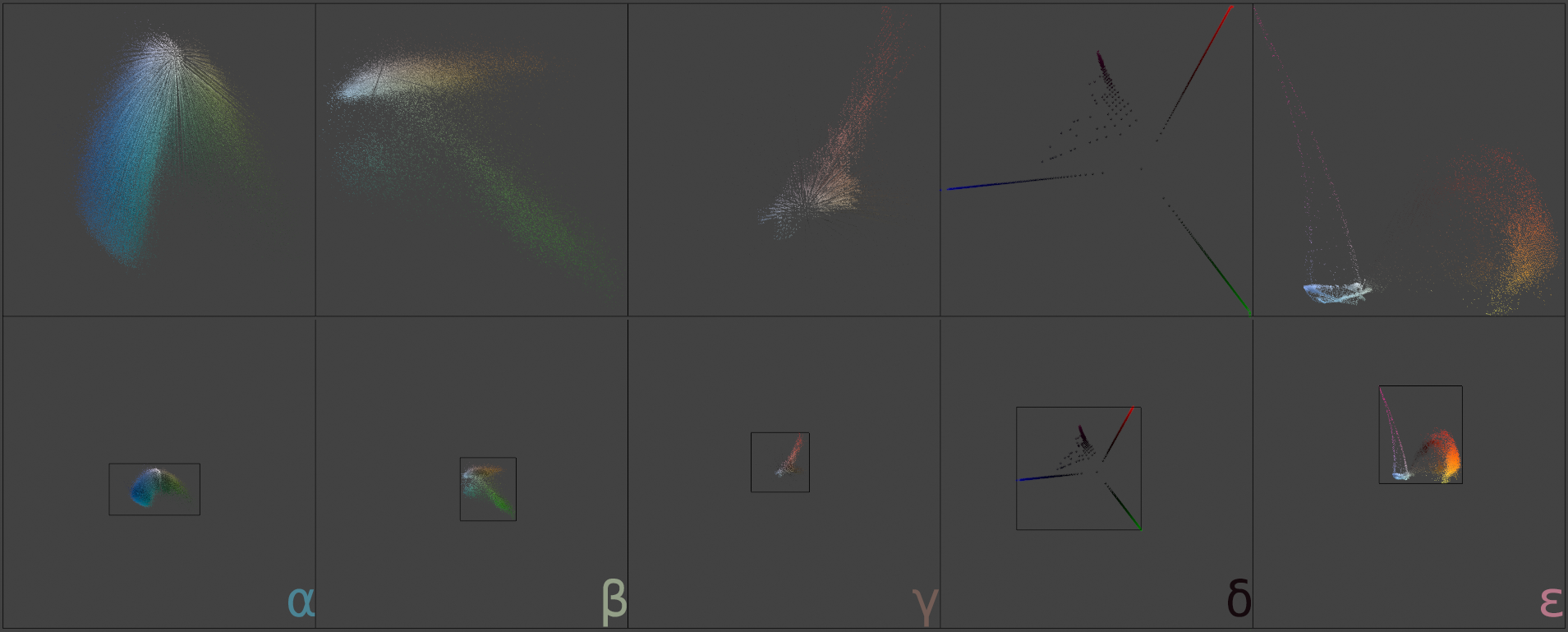
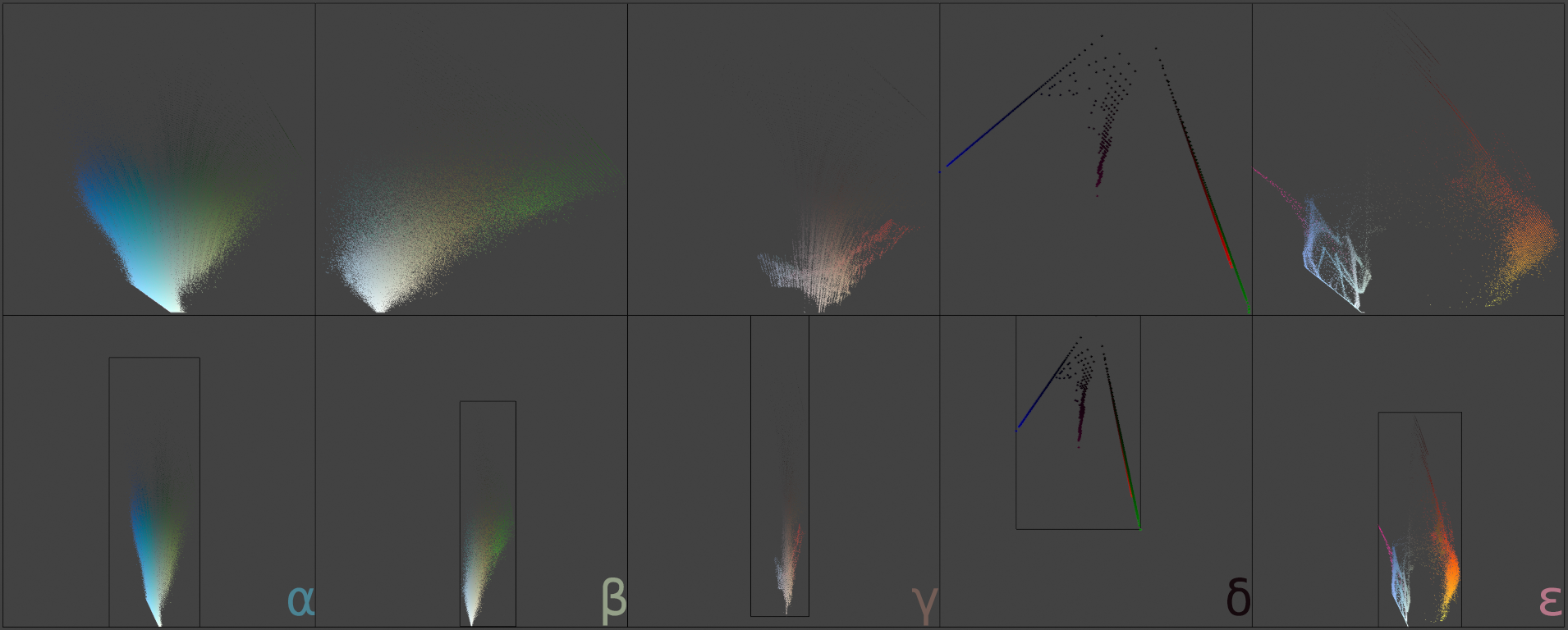
As is hopefully obvious from the figures, the range of [[P]] actually used by any given input tends to be quite narrow, so subdividing [[P]] directly will yield poor occupancy. Indeed, for the datasets visualised above:
| volume | bounding box | |||||
|---|---|---|---|---|---|---|
| α | ≈0.041316 | [[[0.13635494, 1.0]]] | [[\times]] | [[[-0.13823886, 0.02675569]]] | [[\times]] | [[[-0.16005541, 0.12989232]]] |
| β | ≈0.026181 | [[[0.27619627, 0.9986911]]] | [[\times]] | [[[-0.15646803, 0.04568255]]] | [[\times]] | [[[-0.037055194, 0.1422047]]] |
| γ | ≈0.034417 | [[[0.0, 0.9665335]]] | [[\times]] | [[[-0.06452984, 0.12635213]]] | [[\times]] | [[[-0.10584019, 0.08071107]]] |
| δ | ≈0.107448 | [[[0.0, 0.68679345]]] | [[\times]] | [[[-0.18539383, 0.20771612]]] | [[\times]] | [[[-0.2556958, 0.14228153]]] |
| ε | ≈0.057179 | [[[0.31232694, 1.0]]] | [[\times]] | [[[-0.03692481, 0.27541596]]] | [[\times]] | [[[-0.09577876, 0.17043555]]] |
so, with Oklab [[P]]'s volume being 1, the average bounds are just 5.33% of that!
For a cartesian grid of dimension [[G \in \mathbb{N}_+]] we can define a bijective map [[g : P \to [0, G )^3]] such that
a bare definition of [[g]] (without [[\min]]) would also include [[{G}^3]] in the codomain for points on the far extrema of the bounding box; we abuse the fact that we don't actually use [[g^{-1}(g(p))]] as data, just as optimisation metadata, to make it much more useful (the error induced is imperceptible after quantisation later): the grid cell each [[p]] falls in is given by [[\operatorname{trunc}(g(p)) \in \bar{G}^3]]. The points within each cell [[h : \bar{G}^3 \to \mathcal{P}(D)]] can then be obtained by computing [[h(x) = \{p | p \in D \wedge \operatorname{trunc}(g(p)) = x\}]]; the desired properties [[h(x) \cap h(y) \ne \varnothing \Leftrightarrow x = y \text{ & } \bigcup (h \circ {\operatorname{trunc}} \circ g \circ D) = D]] are preserved under these mappings.




# box bondage 🥺
Computing [[(B_m, B_M)]] is more-usefully analysed as a [[(\min, \max)]] fold over [[D]] starting at [[(+\infty^3, -\infty^3)]]. To this end, [[\min]] and [[\max]] are available as atomics — HLSL calls them InterlockedMin/-Max even though no locking, inter- or otherwise, takes place; GLSL nomenclature is reasonable, so this is an unforced error on Microsoft's part — but only on integers, which coordinates in [[D]] aren't.
But they are IEEE754 floats, which have a well-behaved structure when interpreted as-if they were integers.
Indeed, if [[P]] were in the form [[[0, x]^3]], no further processing would be required,
since positive floats compare the same as uints
(other relations can be drawn, cf.
No. Two floating point values (IEEE 754 binary64) cannot compare, chux, 2015).
But it isn't, so we desire a bijection [[u : float \to uint \text{ or } int]] monotonic in [[(-\infty, +\infty)]],
ideally something I don't have to derive because that sucks battle-tested.
The literature provides
Bullet 2.81, GPU Soft Body Solvers, DX11, Erwin Coumans &a., 2012
(and [[u^{-1}]]),
for 32-bit floats and uints
(notationally, this is where real math (Wikipedia lists operators in [[\LaTeX]]) ends and "computer science" (Wikipedia l. op. in Courier) begins):
u(f) = asuint(f) ^ ((~(asuint(f) >> 31) + 1) | 0x8000`0000) u-1(u) = asfloat(u ^ (( ( u >> 31) - 1) | 0x8000`0000))(with logical
>> and wrap-around +/-;
asuint()/asfloat() like in HLSL or Rust f32::to_bits()/f32::from_bits())
Within the [[(-\infty, +\infty)]] domain, IEEE754 floats consist of [[(1\ \text{sign bit})(31\ \text{bits of distance from}\ 0\ \text{in natural }\texttt{uint}\text{ sort order})]]. There's more stuff in there but it's not relevant here; Google float \infty to learn more. The [[l]] axis from example β can thus be transcoded as
| asuint(f) | ^ | ( | ( | ~ | ( | asuint(f) | >> 31 | ) | + 1) | | 0x8000`0000 | ) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xBE20`3928 | ^ | ( | ( | ~ | ( | 0xBE20`3928 | >> 31 | ) | + 1) | | 0x8000`0000 | ) |
| 0xBE20`3928 | ^ | ( | ( | ~ | ( | 1 | ) | + 1) | | 0x8000`0000 | ) | |
| 0xBE20`3928 | ^ | ( | ( | 0xFFFF`FFFE | + 1) | | 0x8000`0000 | ) | ||||
| 0xBE20`3928 | ^ | ( | 0xFFFF`FFFF | | 0x8000`0000 | ) | ||||||
| 0xBE20`3928 | ^ | 0xFFFF`FFFF | |||||||||
| 0x41DF`C6D7 | ∎ | ||||||||||
| asfloat( | u | ^ | ( | ( | (u | >> 31) | - 1) | | 0x8000`0000) | ) |
|---|---|---|---|---|---|---|---|---|---|
| asfloat( | 0x41DF`C6D7 | ^ | ( | ( | (0x41DF`C6D7 | >> 31) | - 1) | | 0x8000`0000) | ) |
| asfloat( | 0x41DF`C6D7 | ^ | ( | ( | 0 | - 1) | | 0x8000`0000) | ) | |
| asfloat( | 0x41DF`C6D7 | ^ | ( | 0xFFFF`FFFF | | 0x8000`0000) | ) | |||
| asfloat( | 0x41DF`C6D7 | ^ | 0xFFFF`FFFF | ) | |||||
| asfloat( | 0xBE20`3928 | ) | |||||||
| −0.15646803 | ∎ | ||||||||
| asuint(f) | ^ | ( | ( | ~ | ( | asuint(f) | >> 31 | ) | + 1) | | 0x8000`0000 | ) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x3D3B`1DA0 | ^ | ( | ( | ~ | ( | 0x3D3B`1DA0 | >> 31 | ) | + 1) | | 0x8000`0000 | ) |
| 0x3D3B`1DA0 | ^ | ( | ( | ~ | ( | 0 | ) | + 1) | | 0x8000`0000 | ) | |
| 0x3D3B`1DA0 | ^ | ( | ( | 0xFFFF`FFFF | + 1) | | 0x8000`0000 | ) | ||||
| 0x3D3B`1DA0 | ^ | ( | 0 | | 0x8000`0000 | ) | ||||||
| 0x3D3B`1DA0 | ^ | 0x8000`0000 | |||||||||
| 0xBD3B`1DA0 | ∎ | ||||||||||
| asfloat( | u | ^ | ( | ( | (u | >> 31) | - 1) | | 0x8000`0000) | ) |
|---|---|---|---|---|---|---|---|---|---|
| asfloat( | 0xBD3B`1DA0 | ^ | ( | ( | (0xBD3B`1DA0 | >> 31) | - 1) | | 0x8000`0000) | ) |
| asfloat( | 0xBD3B`1DA0 | ^ | ( | ( | 1 | - 1) | | 0x8000`0000) | ) | |
| asfloat( | 0xBD3B`1DA0 | ^ | ( | 0 | | 0x8000`0000) | ) | |||
| asfloat( | 0xBD3B`1DA0 | ^ | 0x8000`0000 | ) | |||||
| asfloat( | 0x3D3B`1DA0 | ) | |||||||
| 0.04568255 | ∎ | ||||||||
This reveals some core insights:
- [[\begin{align} \text{If}\ sgn(f) \text{:}\\ u(f) &= f \oplus \mathrm{FFFFFFFF}_{16} = \neg f\\ u^{-1}(u) &= u \oplus \mathrm{FFFFFFFF}_{16} = \neg u\\ \text{Otherwise:}\\ u(f) &= f \oplus \mathrm{80000000}_{16}\\ u^{-1}(u) &= u \oplus \mathrm{80000000}_{16} \end{align}]]
- the sign bit is always flipped, yielding the top bit set for positive fs and clear for negative fs, inducing a clear partition:
u( 0.0) = 0x8000`0000 = 0b1000`0000`0000`0000`0000`0000`0000`0000
u(−0.0) = 0x7FFF`FFFF = 0b0111`1111`1111`1111`1111`1111`1111`1111
but this means that the condition is mirrored between u and u-1 - since the remaining bits are "distance from zero", so more negative numbers are larger, they are flipped so more negative numbers are smaller
- functionally, this is basically most of a (sign + magnitude) ↔ (two's complement) implementation
(just missing the
+ 1at the end for negative numbers) - both major optimisers (and, accd'g to my measurements, all three GPU driver optimisers) turn ~(f >> 31) + 1 into f >>arithmetic 31 (since the desired state equvalent to the top bit being copied to every other bit, which a sign-extension all the way down will do); this reduces u from (lsr31,neg,add,or,xor) to (asr31,or,xor) which is unbeatable
- this could be more clearly (but less goodly since it induces a branch) be expressed ideologically as
u(f) = asuint(f) ^ (0xFFFF`FFFF if (asuint(f) & 0x8000`0000) else 0x8000`0000) u-1(u) = asfloat(u ^ (0xFFFF`FFFF if not (u & 0x8000`0000) else 0x8000`0000)
[[B_m]] and [[B_M]]/[[B_r]] can be allocated directly, minding the free scalars in each 4-primitive block.
Since the reduxion wants to do atomic operations on integers (and no aliasing is possible),
these must be declared as uint3s for that shader, and may be float3 in others;
theoretically it's possible to keep known_rgbs_pack::lab as a float3
and bit-cast with asuint() but there's no reason to do this.
So, lifting the declaration to
a common shader.h:
struct params_t {
uint known_rgbs_len;
float radiussy_squared;
int iter_limit;
uint _padding1;
point_t bbox_min;
uint _padding2;
point_t bbox_range;
uint _padding3;
#define bbox_max bbox_range // find_bbox.hlsl only
};
struct known_rgbs_pack {
point_t lab;
uint rgb;
};
thus,
find_bbox.hlsl
can typedef point_t one way, and everything else — the other
(also note how Bullet 2.81 does it a little goofy and applies u per-component; there is no reason to do this):
typedef uint3 point_t;
#include "shader.h"
[[vk::binding(1)]] RWStructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
uint3 tmp = known_rgbs_bundle[id].lab;
tmp ^= (~(tmp >> 31) + 1) | 0x80000000;
InterlockedMin(params[0].bbox_min.x, tmp.x);
InterlockedMin(params[0].bbox_min.y, tmp.y);
InterlockedMin(params[0].bbox_min.z, tmp.z);
InterlockedMax(params[0].bbox_max.x, tmp.x);
InterlockedMax(params[0].bbox_max.y, tmp.y);
InterlockedMax(params[0].bbox_max.z, tmp.z);
}
and the driver just needs to supply the integral equivalent of [[(+\infty^3, -\infty^3)]] and post-process with u-1 (this is where a real enum would've been nice):
const FIND_BBOX: usize = 2;
const SHADER_COUNT: usize = FIND_BBOX + 1;
static SHADER_DATA: [&[u32]; SHADER_COUNT] = [include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise_mul.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/find_bbox.spv"))];
pub struct PosteriseGpu {
// ...
compute_pipeline: Vec<vk::Pipeline>, // [SHADER_COUNT]
}
#[repr(C)]
struct ParamsT {
known_rgbs_len: u32,
radiussy_squared: f32,
iter_limit: i32,
_padding1: u32,
bbox_min: [f32; 3],
_padding2: u32,
bbox_range: [f32; 3],
_padding3: u32,
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
self.buffer_params_map = ParamsT {
known_rgbs_len: known_rgbs.len(),
radiussy: radiussy,
iter_limit: -1,
bbox_min: [f32::from_bits(0xFFFFFFFF); 3];
bbox_range /* as bbox_max */: [f32::from_bits(0x00000000); 3];
_padding1: 0, _padding2: 0, _padding3: 0,
};
// ...
// find_bbox.hlsl
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[FIND_BBOX]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len().div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
fn become_float3(bbox: &[f32; 3]) -> [f32; 3] {
bbox.map(f32::to_bits).map(|bu| f32::from_bits(bu ^ ((bu >> 31).wrapping_sub(1) | 0x80000000)))
}
{
let bbox_min = become_float3(&self.buffer_params_map.bbox_min);
let bbox_range = {
let bbox_max = become_float3(&self.buffer_params_map.bbox_range);
[bbox_max[0] - bbox_min[0], bbox_max[1] - bbox_min[1], bbox_max[2] - bbox_min[2]]
};
self.buffer_params_map.bbox_min = bbox_min;
self.buffer_params_map.bbox_range = bbox_range;
}
// ... posterise.hlsl/posterise_mul.hlsl &c.
}
This takes anywhere between 120-400µs on the images in the test dataset on the 5700 XT, but variance is so high at this scale that this is barely correlated with the input size (amount of distinct colours). Functionally this is as good as instant. Bench-marking on orders-of-magnitude more data shows throughput of around 414'419'783 uint3/s. The next generation (NVIDIA RTX 4070 SUPER/AMD Radeon RX 6500 XT (RADV NAVI24)) gets 8'221'135'253/8'383'953'229!
# he do b hittin it doe
With all the parameters to grid [[g]] figured out, we can compute "which points live in each grid cell" [[h]].
This is relatively trivial, except the GPU has no structured programming capabilities,
so the natural uint3 → Vec<indices of known_rgbs/[[D]]> mapping is inexpressible.
The obvious-to-me solution is partitioning all indices by the grid cell they belong to,
then the map becomes uint3 → [begin, end) iteratorsindices;
this seems canonical.
The original example
(if we force [[B_m = (0,\frac{-1}{2},\frac{-1}{2}); B_r = (1,1,1)]] and specify [[G=10]])

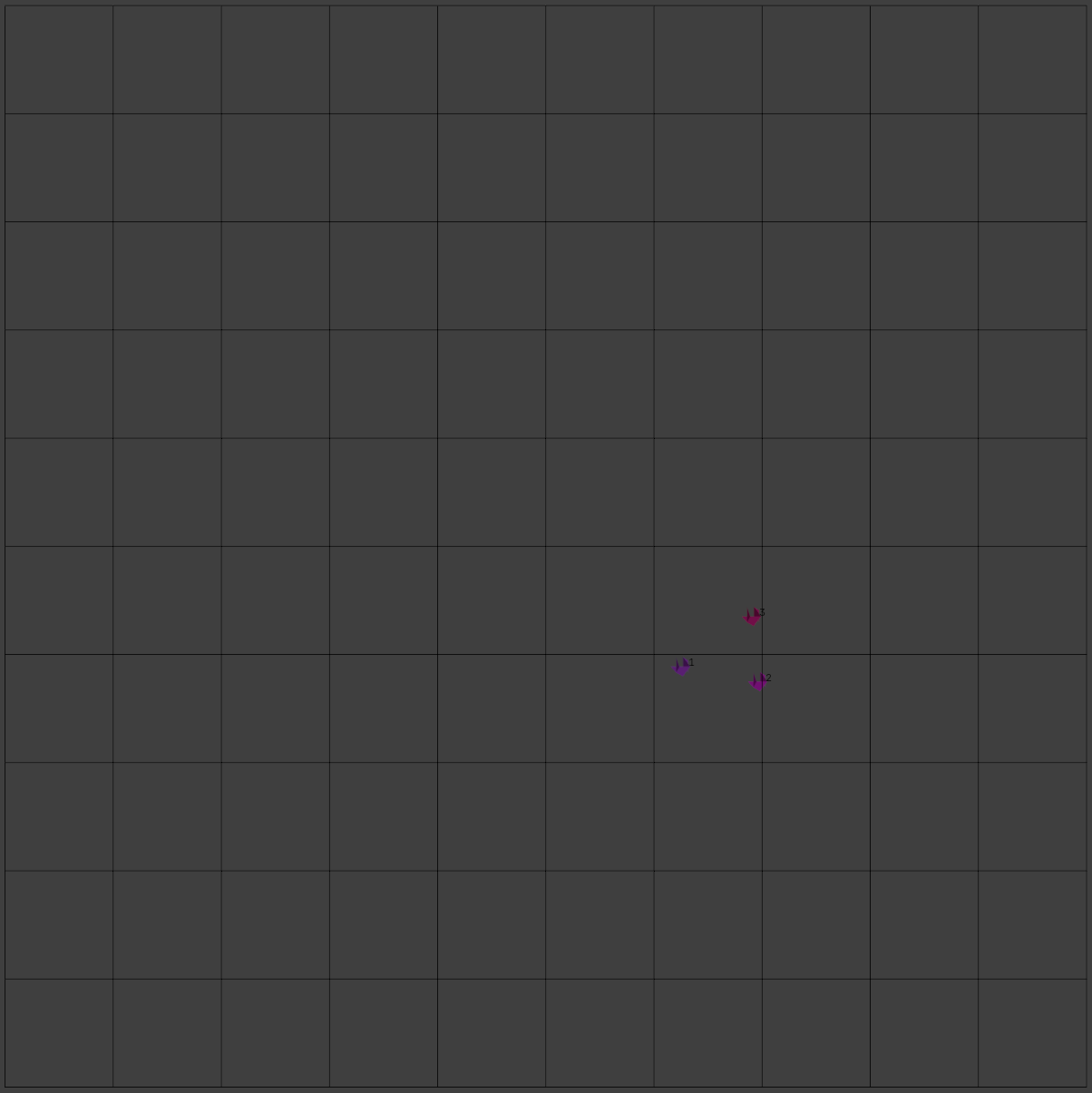

Thus, the grid cells occupied are, resp. [[(7, 6, 3)]], [[(7, 6, 3)]], and [[(7, 6, 4)]]. The backing storage can then be [[(1, 2, 3)]], and the map can take the form
since all other cells are empty. (The backing storage could also be [[(3, 2, 1)]], and the map return [[[2, 4)]]/[[[1, 1)]].)
Realistically, both the map and backing storage are "a big array" — of uint2s with dimension [[G^3]] and uints with dimension [[\overline{Set(D)}]] respectively. It's theoretically possible to implement [[h]] by collecting the points for each grid cell coordinate separately, like the definition, but this would be [[O(n^2)]], so pre-calculating the grid cell coordinates for each point, then collecting them, is [[O(n)]]. To that end, with [[g]] as lab_to_gridpos and [[G]] as GRID_SIZE, shader.h:
#define GRID_SIZE 100
struct groupdesc_t {
uint start_idx, end_idx;
};
struct params_t {
// ...
groupdesc_t group_ranges[GRID_SIZE][GRID_SIZE][GRID_SIZE];
};
// ...
float3 lab_to_gridpos(float3 pos, float3 bbox_min, float3 bbox_range) {
pos = (pos - bbox_min) / bbox_range;
return min(pos * GRID_SIZE, GRID_SIZE - 0.001);
}
groupdesc_t has the same lay-out as uint2, and putting it in an array like this doesn't induce additional padding. The total size of params_t, and, thus, usage of precious DEVICE_LOCAL & HOST_VISIBLE & HOST_COHERENT memory, grows by [[G^3 \operatorname{sizeof}(\texttt{uint2}) = 8\text{MB}]], which is good to know but otherwise negligible.
[[g]]'s [[\varepsilon = 0.001]] is just as good as any other value (so long as it actually exists around [[G]]); the optimiser lowers this to a constant. The pre-computation can thus be [[\operatorname{trunc} \circ g]] directly in assign_cell.hlsl:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(0)]] RWStructuredBuffer<uint> outputs; // HOST_VISIBLE
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const float3 bbox_min = params[0].bbox_min;
const float3 bbox_range = params[0].bbox_range;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
uint3 gridpos = trunc(lab_to_gridpos(known_rgbs_bundle[id].lab, bbox_min, bbox_range));
outputs[id] = (gridpos.x << (8 * 2)) |
(gridpos.y << (8 * 1)) |
(gridpos.z << (8 * 0));
}
this abuses outputs as an output buffer —
this is fine, since the size used is [[\texttt{known_rgbs.len()} \cdot \operatorname{sizeof}(\texttt{uint})]],
and the allocation is [[2^{24} \operatorname{sizeof}(\texttt{float4})]],
which is guaranteed to be at least 4× larger.
Obviously the packing would need to be changed for [[G > \mathrm{FF}_{16}]].
This will not pose an issue.
Shaders can include shader.h to have one source of truth for [[G]], but the Rust driver can't. This is emulated in build.rs:
fn main() {
let grid_size = fs::read_to_string("src/shader.h").lines()
.find(|l| l.contains("#define GRID_SIZE")).split_whitespace().last();
fs::write(Path::new(&env::var_os("OUT_DIR")).join("grid_size.rs"), &grid_size);
// ... glslc
}
So, with, [[h]] as groups_data:
const ASSIGN_CELL: usize = FIND_BBOX + 1; // &c.
const GRID_SIZE: usize = include!(concat!(env!("OUT_DIR"), "/grid_size.rs"));
#[repr(C)]
struct GroupDesc {
start_idx: u32,
end_idx: u32,
}
#[repr(C)]
struct ParamsT {
// ...
group_ranges: [[[GroupDesc; GRID_SIZE]; GRID_SIZE]; GRID_SIZE],
}
const SHADER_MAX_BINDING: u32 = 4;
pub struct PosteriseGpu {
// ...
buffer_outputs: BufferBundle, // [[vk::binding(0)]] SB<float3> outputs; [HOST_VISIBLE]
buffer_params: BufferBundle, // [[vk::binding(1)]] SB<params_t> params; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_known_rgbs_bundle: BufferBundle, // [[vk::binding(2)]] SB<known_rgbs_pack> known_rgbs_bundle; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_known_rgbs_freqs: BufferBundle, // [[vk::binding(3)]] SB<uint> known_rgbs_freqs; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_groups_data: BufferBundle, // [[vk::binding(4)]] SB<uint> groups_data; [DEVICE_LOCAL]
groups_accumulator: Box<[[[Vec<u32>; GRID_SIZE]; GRID_SIZE]; GRID_SIZE]>,
}
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
let physical_device_properties = vk_instance.get_physical_device_properties(physical_device);
assert!(SHADER_MAX_BINDING < physical_device_properties.limits.max_bound_descriptor_sets);
let output_memory_type_index = memory_types.iter()
.position(|memory_type| {
memory_type.property_flags.contains(vk::MemoryPropertyFlags::HOST_VISIBLE) &&
memory_type.property_flags.contains(vk::MemoryPropertyFlags::HOST_COHERENT)
})
.expect("No output memory type");
let input_memory_type_index = memory_types.iter()
.position(|memory_type| {
memory_type.property_flags.contains(vk::MemoryPropertyFlags::DEVICE_LOCAL) &&
memory_type.property_flags.contains(vk::MemoryPropertyFlags::HOST_VISIBLE) &&
memory_type.property_flags.contains(vk::MemoryPropertyFlags::HOST_COHERENT)
})
.unwrap_or(output_memory_type_index);
let input_memory_type_index = memory_types.iter()
.position(|memory_type| memory_type.property_flags.contains(vk::MemoryPropertyFlags::DEVICE_LOCAL))
.unwrap_or(output_memory_type_index);
// vk::BufferUsageFlags::STORAGE_BUFFER | ::TRANSFER_SRC ⬎ ⬐ ::TRANSFER_DST
ret.buffer_outputs = BufferBundle(output_memory_type_index, true, false);
ret.buffer_params = BufferBundle(input_memory_type_index, false, true);
ret.buffer_known_rgbs_bundle = BufferBundle(input_memory_type_index, false, false);
ret.buffer_known_rgbs_freqs = BufferBundle(input_memory_type_index, false, false);
ret.buffer_groups_data = BufferBundle(private_memory_type_index, false, true);
unsafe {
ret.groups_accumulator = Box::<mem::MaybeUninit<_>>::assume_init(Box::new_uninit()),
for ga in ret.groups_accumulator.iter_mut().flatten().flatten() {
ptr::write(ga as *mut _, Vec::new());
}
}
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
self.buffer_groups_data.ensure_buffer(known_rgbs.len() * mem::size_of::<u32>());
if freq_weighting {
self.buffer_known_rgbs_freqs.ensure_buffer(known_rgbs.len() * mem::size_of::<u32>());
}
// ...
// memset(self.buffer_params.buffer, 0, *); ⇔ self.buffer_params_map = mem::zeroed();
self.device.cmd_fill_buffer(self.cmd_buffer, self.buffer_params.buffer, 0, vk::WHOLE_SIZE, 0);
self.submit_buffer(self.cmd_buffer);
{
self.buffer_params_map.known_rgbs_len = known_rgbs.len();
self.buffer_params_map.bbox_min = [f32::from_bits(0xFFFFFFFF); 3];
// bbox_range/bbox_max already = 0x00000000 from memset()
self.buffer_params_map.radiussy_squared = radiussy * radiussy;
self.buffer_params_map.iter_limit = -1;
}
// ... through find_bbox.hlsl &c.
// assign_cell.hlsl
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[ASSIGN_CELL]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len().div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
// grouping
let known_rgbs_groupcoords: &mut [u32] = slice::from_raw_parts_mut(self.buffer_outputs_map.as_ptr(), known_rgbs.len());
for group in self.groups_accumulator.iter_mut().flatten().flatten() {
group.clear();
}
for (id, groupcoord) in known_rgbs_groupcoords.iter().enumerate() {
let (x, y, z) = ((groupcoord >> (8 * 2)),
(groupcoord >> (8 * 1)) & 0xFF,
(groupcoord >> (8 * 0)) & 0xFF);
self.groups_accumulator[x][y][z].push(id);
}
// copying
let mut known_rgbs_groups: *mut u32 = self.buffer_outputs_map.as_ptr() as _;
let mut cur = 0;
for (gr_z, ga_z) in self.buffer_params_map.group_ranges.iter_mut().flatten().flatten()
.zip(self.groups_accumulator .iter() .flatten().flatten()) {
if ga_z.len() != 0 {
let start = cur;
// memcpy(known_rgbs_groups, ga_z.as_ptr(), ga_z.len())
known_rgbs_groups.copy_from_nonoverlapping(ga_z.as_ptr(), ga_z.len());
cur += ga_z.len();
known_rgbs_groups = known_rgbs_groups.add(ga_z.len());
*gr_z = GroupDesc {
start_idx: start,
end_idx: cur,
};
}
}
assert!(cur == known_rgbs.len());
// memcpy(self.buffer_groups_data, self.buffer_outputs, known_rgbs * mem::size_of::<u32>());
self.device.cmd_copy_buffer(self.cmd_buffer, self.buffer_outputs.buffer, self.buffer_groups_data.buffer,
&[vk::BufferCopy {
src_offset: 0,
dst_offset: 0,
size: known_rgbs * mem::size_of::<u32>(),
}]);
self.submit_buffer(self.cmd_buffer);
// ... posterise.hlsl/posterise_mul.hlsl &c.
}
This is the first time more than the aforementioned 4 bindings are used; checking this a priori potentially avoids a more confusing error later, but this will never be triggered on real implementations.
groups_data is, from the perspective of the host, write-only/write-once for each image,
so it can live in DEVICE_LOCAL memory and be uploaded via outputs
(AIUI this technique is called the "staging buffer";
bounds used same as find_bbox.hlsl's).
This also means that they need to be allocated with the right TRANSFER_direction flags.
groups_accumulator is a similar size to the [[8\text{MB}]] — [[G^3 \cdot \operatorname{sizeof}(\texttt{Vec<_>}) = G^3 \cdot 3 \operatorname{sizeof}(\texttt{usize}) = 24\text{MB}_\text{LP64} \vee 12\text{MB}_\text{ILP32}]] would blow any stack and it's impossible to use objects too large to spill in Rust (I tried!), so it needs to go in an additional allocation and then be initialised piece-meal. Vecs can't be all-0 so is it in principle UB to assume_init(new_uninit()), then force-initialise them? Maybe. Is this a real concern? no.
Like-wise due to its size, params can no longer be cleared by re-assignment (it'd be a memcpy(mapping ← stack)), and it makes no sense to clear it with an actual memset(), effectively uploading [[8\text{MB}]] of zeroes to DEVICE_LOCAL memory. Thus, a device-side memset — vkCmdFillBuffer() — is dispatched, working exactly as you'd expect (except it sets whole uints instead of bytes), and completing too quickly to measure above the fixed submission overhead of a couple dozen μs. From the point of buffer usage, this is a transfer from a null page, hence TRANSFER_DST.
Collecting the indices in each cell (grouping
) is expensive but can't be meaningfully sped up.
Neither can copying
the data, beyond only copying the index ranges for non-empty cells
(after the memset, the default value is [[[0, 0 ) = \varnothing]] which is what we'd be writing anyway),
but that is relatively quick:
| (colours) | 16'755 | 242'931 | 328'666 | 1'103'347 | ±σ |
|---|---|---|---|---|---|
| assign_cell.hlsl | 77.0µs | 225.3µs | 274.9µs | 737.3µs | 12µs/15µs/15µs/20µs |
grouping | 5.160ms | 24.060ms | 32.644ms | 94.377ms | 1.339ms/1.051ms/1.410ms/4.375ms |
| grouping speed | 3246792 | 10097073 | 10068170 | 11690922 | [points/s] |
copying | 2.980ms | 4.717ms | 5.932ms | 8.905ms | 564µs/315µs/404µs/500µs |
| GroupDescs copied | 6523 | 66589 | 104645 | 167428 | = cells occupied; out of 1003 |
| …if w/o [[B_m]]/[[B_r]] scaling | 2260 | 6979 | 10662 | 53492 | '' |
| memcpy | 388.2µs | 436.3µs | 650.5µs | 912.4µs | 23µs/31µs/2µs/57µs |
| memcpy size | 67kB | 972kB | 1315kB | 4413kB |
So grouping
, on the i7-2600, quickly arrives at a consistent ~11Mp/s throughput.
Bounding box scaling clearly works, increasing the occupancy, in the case of the 1'103'347 image, from ~5%
(average population of ~20 in non-empty cells, median 9)
to ~17% (~7, 3).
# The grid-based mean-shift clustering shader implementation,
thus, can take advantage of the grid by, instead of checking if all elements of [[D]] are closer to [[q_t]] than [[r]], considering only the ones that could feasibly fulfil that predicate by virtue of being contained within near-by grid cells. The actual range is complicated slightly by the bounding box scale being different along each axis, so the sphere of influence (with a cubic bounding box) turns into an ellipsoid of influence with "radiuses" [[R]] (with a prismatic bounding box from [[g_{tm}]] to [[g_{tM}]]) rounded up to encompas any cell it intersects after the [[B_r]] scaling:
With [[R]] as grid_bothdirs, [[g_t]] as gridpos, [[g_{tm}]] as gridpos_from, and [[g_{tM}]] as gridpos_to, posterise_grid_kernel.hlsl.inc can implement the [[\bigcup]] literally:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(0)]] RWStructuredBuffer<float3> outputs; // HOST_VISIBLE
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
/* 3 */ KNOWN_RGBS_FREQS
[[vk::binding(4)]] StructuredBuffer<uint> groups_data; // DEVICE_LOCAL
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const float radiussy_squared = params[0].radiussy_squared;
const uint iter_limit = params[0].iter_limit;
const float3 bbox_min = params[0].bbox_min;
const float3 bbox_range = params[0].bbox_range;
const uint3 grid_bothdir = params[0].grid_bothdirs;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
known_rgbs_pack this = known_rgbs_bundle[id];
float3 center = this.lab;
for(int iter = 0; iter != iter_limit; ++iter) {
const uint3 gridpos = trunc(lab_to_gridpos(center, bbox_min, bbox_range));
const uint3 gridpos_from = gridpos - min(grid_bothdirs, gridpos);
const uint3 gridpos_to = min(gridpos + grid_bothdirs, GRID_SIZE - 1);
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint gx = gridpos_from.x; gx <= gridpos_to.x; ++gx)
for(uint gy = gridpos_from.y; gy <= gridpos_to.y; ++gy)
for(uint gz = gridpos_from.z; gz <= gridpos_to.z; ++gz) {
groupdesc_t group = params[0].group_ranges[gx][gy][gz];
for(; group.start_idx != group.end_idx; ++group.start_idx) {
const uint i = groups_data[group.start_idx];
float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
#if !BRANCHLESS_ADD
if(matched)
#endif
{
FREQ_LOAD
newcenter_count += FREQ;
newcenter += FREQ_MUL lab;
}
}
}
newcenter /= newcenter_count;
bool same = newcenter == center;
if(same)
break;
center = newcenter;
}
outputs[this.rgb] = center;
}
posterise_grid.hlsl and posterise_grid_mul.hlsl are unchanged, and so is both the outer-most [[q_t]] loop and inner-most [[\Sigma]]. To avoid overflow if [[R > g_t]] we observe [[\max(g_t - R, (0, 0, 0)) = g_t - \min(R, g_t)]].
Reordering the scalar parameters to forced-padding locations allows retaining the same size while fitting grid_bothdirs/[[R]]:
struct params_t {
uint3 grid_bothdirs;
uint known_rgbs_len;
point_t bbox_min;
float radiussy_squared;
point_t bbox_range;
int iter_limit;
#define bbox_max bbox_range
groupdesc_t group_ranges[GRID_SIZE][GRID_SIZE][GRID_SIZE];
};
[[R]] computation is can likewise be implemented directly:
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
// ...
// find_bbox.hlsl ...
{
let bbox_min = become_float3(&self.buffer_params_map.bbox_min);
let bbox_range = {
let bbox_max = become_float3(&self.buffer_params_map.bbox_range);
[bbox_max[0] - bbox_min[0], bbox_max[1] - bbox_min[1], bbox_max[2] - bbox_min[2]]
};
self.buffer_params_map.bbox_min = bbox_min;
self.buffer_params_map.bbox_range = bbox_range;
let scaled_radiussies = bbox_range.map(|scale| radiussy / scale);
let direction_cells = scaled_radiussies.map(|sr| (sr * GRID_SIZE).ceil());
self.buffer_params_map.grid_bothdirs = direction_cells;
}
// ...
}
By mildly instrumenting (dbg!(direction_cells)) or recalling the bounding boxes from before, we can compute the following and use it as the best-case prediction (additionally assuming every cell inspected will be non-empty, which it won't, but non-empty cells are where the points are so they're roughly where [[q_t]]s are and they're pretty dense, so.):
| (colours) | 16'755 | 242'931 | 328'666 | 1'103'347 |
|---|---|---|---|---|
| [[R]] | 3×7×8 | 3×1×7 | 3×8×10 | 2×5×4 |
| Volume between [[g_{tm}]] and [[g_{tM}]] when not near an edge | 1785 | 315 | 2499 | 495 |
| Average points inspected when not near an edge | 4585 | 1149 | 7849 | 3262 |
| Projected average speed-up | 72.64% | 99.53% | 97.61% | 99.70% |
To contrast with real performance data:
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 116.646ms | 99.415ms | 85.23% |
| (speed-up vs previous) | 5.49% | 12.35% | -6.68 p.p. |
| (speed-up vs base-line) | 9.47% | 16.36% | -7.02 p.p. |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 115.426ms | 144.812ms | 125.46% |
| (speed-up vs previous) | 6.75% | 1.54% | 6.63 p.p. |
| (speed-up vs base-line) | 11.87% | 4.64% | 9.51 p.p. |
[[*freq]] becomes more slower than [[palette]] in the degenerate case and less slower than [[palette]] on the real image. What this means is unclear to me.
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 116.65ms | 4.198s | [time-out; ~109/155] | 5ms/214ms/– |
| (speed-up vs base-line) | 10% | 36% | 4% | |
| 5700 XT, [[*freq]] | 99.42ms | 3.286s | [time-out; ~190/152] | 782µs/332ms/– |
| (speed-up vs base-line) | 18% | 25% | 31% | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 1.891s | [time-out; ~73/220] | [time-out; ~9560/6505] | 400ms/–/– |
| (speed-up vs base-line) | -30% | ∞ | 42.58× | |
| 5700 XT, [[*freq]] | 567.45ms | [time-out; ~143/132] | [time-out; ~7482/5075] | 50ms/–/– |
| (speed-up vs base-line) | -52% | 81% | 4.6× | |
Computation of cells labelled time-outwas terminated by the driver after like 8-11s; progress corresponds to how many distinct output colours ([[\overline{Set(O)}]]) were produced vs. a correct implementation; this is a very vague proxy measured for a very vague amount of time. | ||||
The predictions are entirely uncorrelated with reality. I love economics.

# Failure: GPU-side grid-cell-to-index-list mapping
While the collection (grouping
) can't be sped up on the host, it could, theoretically,
be executed on the GPU by collecting each value of [[h]] directly from the definition by looking at each element of [[D]] for each cell,
after pre-computing the sizes to fix the allocation question.
To that end, the latter can be summed up easily in
assign_cell.hlsl:
// ...
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(3)]] RWStructuredBuffer<uint> known_rgbs_freqs; // DEVICE_LOCAL & HOST_VISIBLE
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
// ...
outputs[id] = (gridpos.x << (8 * 2)) |
(gridpos.y << (8 * 1)) |
(gridpos.z << (8 * 0));
InterlockedAdd(params[0].group_ranges[gridpos.x][gridpos.y][gridpos.z].group_len, 1);
}
(noting that the intermediate map now goes to a non-HOST_VISIBLE memory since it doesn't need to be), after easily restructuring the group index range to [begin, begin+size):
struct groupdesc_t {
uint start_idx, group_len;
};
Thus, the allocator can dump the indices into groups_data in the same manner as the host-side implementation, but instead of doing it in order, it can use Some Global to get the next unused chunk. This is much more like a classical bump allocator. Conveniently, the Some Global can just be the first integer in groups_data. So, the driver is greatly simplified:
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
self.buffer_groups_data.ensure_buffer((known_rgbs.len() + 1) * mem::size_of::<u32>());
// ... through assign_cell.hlsl &c.
// self.buffer_groups_data[0] = 1;
self.device.cmd_fill_buffer(self.cmd_buffer, self.buffer_params.buffer, 0, mem::size_of::<u32>(), 1);
// cicada_grid.hlsl
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[CICADA_GRID]);
self.device.cmd_dispatch(self.cmd_buffer, 1, GRID_SIZE, GRID_SIZE);
self.submit_buffer(self.cmd_buffer);
// ... posterise.hlsl/posterise_mul.hlsl &c.
}
The initial offset must be initialised (to 1 instead of 0 to not overwrite itself), but this can be done in the same command buffer as dispatching the shader and the "couple dozen μs" (like 79±32 in this case) become free. cicada_grid.hlsl is dispatched at [[\text{numthreads} = (G, 1, 1), \text{dispatch}(1, G, G)]] to evaluate every integer in [[h]]'s domain of [[[0, G )^3]]:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(1)]] RWStructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(3)]] StructuredBuffer<uint> known_rgbs_freqs; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(4)]] RWStructuredBuffer<uint> groups_data; // DEVICE_LOCAL
#define next_start groups_data[0]
[numthreads(GRID_SIZE, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint3 gridpos = DTid;
const uint known_rgbs_len = params[0].known_rgbs_len;
const uint my_rgbs = params[0].group_ranges[gridpos.x][gridpos.y][gridpos.z].group_len;
if(my_rgbs == 0)
return;
uint start_idx;
InterlockedAdd(next_start, my_rgbs, start_idx);
params[0].group_ranges[gridpos.x][gridpos.y][gridpos.z].start_idx = start_idx;
const uint gridpos_saved = (gridpos.x << (8 * 2)) |
(gridpos.y << (8 * 1)) |
(gridpos.z << (8 * 0));
for(uint rgb = 0; rgb < known_rgbs_len; ++rgb)
if(known_rgbs_freqs[rgb] == gridpos_saved) {
groups_data[start_idx] = rgb;
++start_idx;
}
}
Visiting every point in [[Set(D)]] for every occupied cell (up to [[G^3]] in theory but cf. occupancy rates above; there are [[G^3]] (so, 1'000'000), threads dispatched though), is, expectedly, ruinous:
| (colours) | 16'755 | 242'931 | 328'666 | 1'103'347 | ±σ |
|---|---|---|---|---|---|
| assign_cell.hlsl | 96.5µs | 113.9µs | 115µs | 156.8µs | 23µs/22µs/22µs/13µs |
| speed-up vs previous | -25.27% | 49.44% | 58.17% | 78.73% | |
grouping+ copying+ memcpy | 5.898ms | 181.893ms | 322.803ms | 1396.184ms | 56µs/374µs/430µs/815µs |
| speed-up vs previous | 32.91% | × | × | × |
Interestingly enough, the cost of uploading to system RAM actually makes up for the additional atomic in all but the smallest cases. But everything else is eye-wateringly worser.
Also, this makes the allocation order basically random. Functionally this is immaterial, but may be tangentially relevant later.
Even another 40× speed-up wouldn't guarantee we can compute every [[f]] within the ~8s driver-imposed limit. But, each shader call could iterate [[t]], like, 10 times. The points that converge can be committed as the final [[f]] mapping as previous, but the ones that don't can be saved and
# processed piece-meal.
The first step here is getting rid of the mis-leading iter_limit in the current shader:
// ...
known_rgbs_pack this = known_rgbs_bundle[id];
#define center this.lab
for(;;) {
// ...
Since the amount of unconverged points decreases each iteration, the [[q_t]] points-to-process array must be compacted between iterations. Well, it doesn't need to be and a thread that just exits instantly could be spawned for it, but this sucks, actively makes occupancy (how many GPU threads are working vs waiting) worse, and basically defeats the purpose; this is already a bit of an issue in the current driver, where it may take 64 pregnant threads where 63 have few fast-to-solve points and 1 that takes long to converge, as long as the latter to bear an output (this is hopefully attenuated slightly by the points being sorted by [[{\color{var(--r)}r\color{initial}}{\color{var(--r)}r\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--b)}b\color{initial}}{\color{var(--b)}b\color{initial}}_{16}]] so similar colours in similar natal situations are carried together, but.). We can store [[q_t]]s and [[q_{t+10}]]s in alternating ranges of a big array and page-flip the input/output iterators (this makes initialisation a memcpy from known_rgbs_bundle as [[q_0]], which is quite nice from a point-and-woo-at-definition perspective):
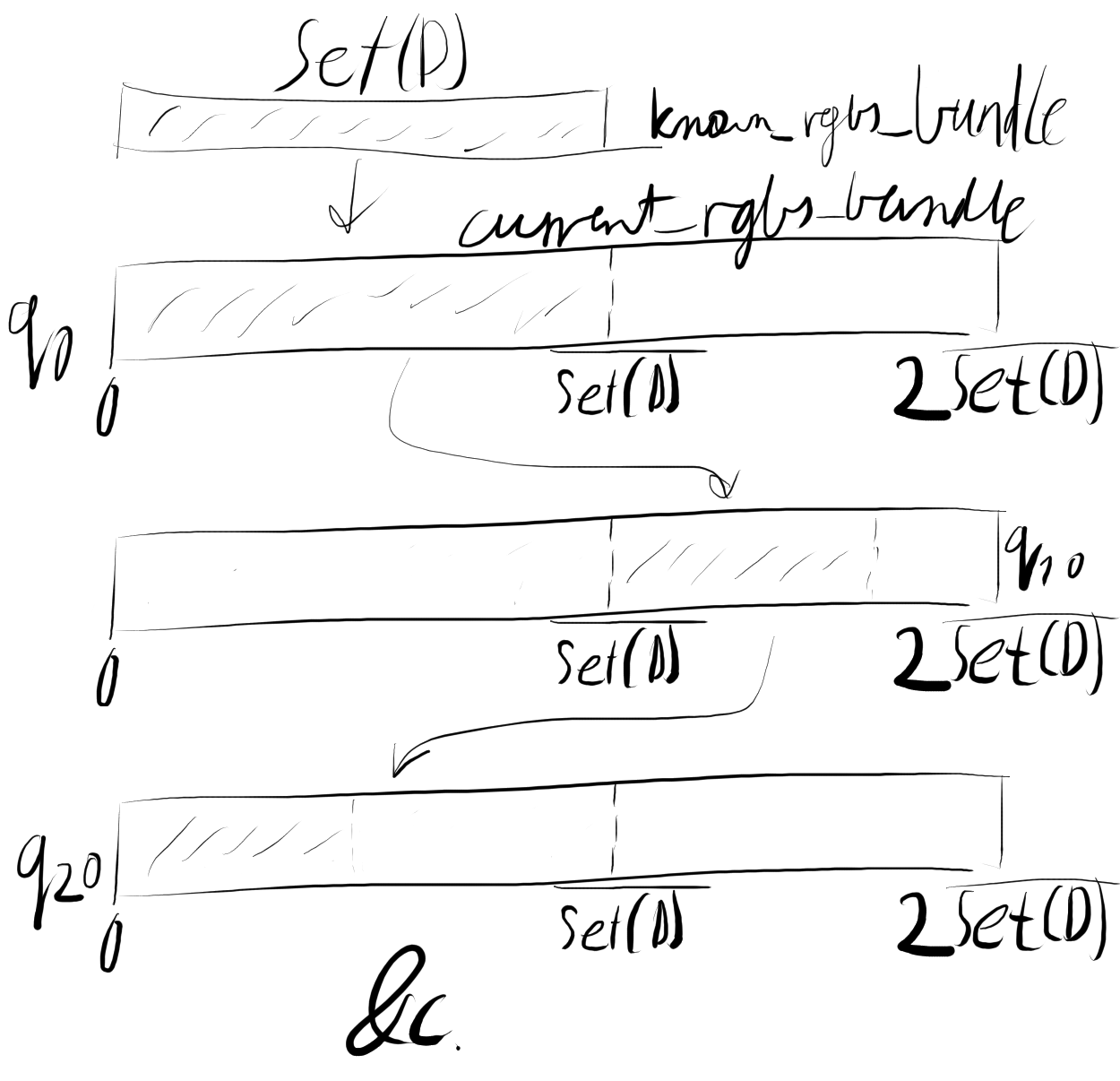
In the current driver, known_rgbs_freqs is indexed by the same offset as known_rgbs_bundle. This is no longer possible once original-index data is lost when the state compacts, so in this case we want to index known_rgbs_freqs by [[{\color{var(--r)}r\color{initial}}{\color{var(--r)}r\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--b)}b\color{initial}}{\color{var(--b)}b\color{initial}}_{16}]] (like outputs), which is kept with the state.
const USEONESHOT: usize = 2;
const FIND_BBOX: usize = USEONESHOT + 2;
const ASSIGN_CELL: usize = FIND_BBOX + 1;
const SHADER_COUNT: usize = ASSIGN_CELL + 1;
static SHADER_DATA: [&[u32]; SHADER_COUNT] = [include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise_grid.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise_grid.mul.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise_grid_oneshot.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/posterise_grid_oneshot.mul.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/find_bbox.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/assign_cell.spv"))];
const SHADER_MAX_BINDING: u32 = 5;
#[repr(C)]
struct ParamsT {
grid_bothdirs: [u32; 3],
known_rgbs_len: u32,
bbox_min: [f32; 3],
radiussy_squared: f32,
bbox_range: [f32; 3],
_padding1: i32,
current_rgbs_start: u32, // [[q_t \in \texttt{current_rgbs_bundle} \circ [\texttt{current_rgbs_start}, \texttt{current_rgbs_start}+\texttt{current_rgbs_len} )]]
current_rgbs_len: u32,
current_rgbs_next: u32, // [[q_{t+\texttt{iter_limit}} \to \texttt{current_rgbs_bundle} \circ [\texttt{current_rgbs_next}, \ldots )]]
iter_limit: i32,
group_ranges: [[[GroupDesc; GRID_SIZE]; GRID_SIZE]; GRID_SIZE],
}
pub struct PosteriseGpu {
// ...
buffer_outputs: BufferBundle, // [[vk::binding(0)]] SB<float3> outputs; [HOST_VISIBLE]
buffer_params: BufferBundle, // [[vk::binding(1)]] SB<params_t> params; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_known_rgbs_bundle: BufferBundle, // [[vk::binding(2)]] SB<known_rgbs_pack> known_rgbs_bundle; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_known_rgbs_freqs: BufferBundle, // [[vk::binding(3)]] SB<uint> known_rgbs_freqs; [DEVICE_LOCAL & HOST_VISIBLE]
buffer_groups_data: BufferBundle, // [[vk::binding(4)]] SB<uint> groups_data; [DEVICE_LOCAL]
buffer_current_rgbs_bundle: BufferBundle, // [[vk::binding(5)]] SB<float4> current_rgbs_bundle; [DEVICE_LOCAL]
// ...
}
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
// vk::BufferUsageFlags::STORAGE_BUFFER | ::TRANSFER_SRC ⬎ ⬐ ::TRANSFER_DST
ret.buffer_known_rgbs_bundle = BufferBundle(input_memory_type_index, true, false); // was false, false
ret.buffer_current_rgbs_bundle = BufferBundle(private_memory_type_index, false, true);
// ...
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, Lab, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [Lab; 0xFFFFFF + 1]) {
let use_oneshot_driver = known_rgbs.len() > 50_000;
self.buffer_known_rgbs_bundle.ensure_buffer(&self.device, known_rgbs.len() * mem::size_of::<KnownRgbsPack>());
assert!(mem::size_of::<KnownRgbsPack>() == 4 * 4);
self.buffer_groups_data.ensure_buffer(&self.device, known_rgbs.len() * mem::size_of::<u32>());
if use_oneshot_driver {
self.buffer_current_rgbs_bundle.ensure_buffer(&self.device, (known_rgbs.len() * 2) * mem::size_of::<KnownRgbsPack>());
}
let buffer_known_rgbs_freqs_len = if use_oneshot_driver { 0xFFFFFF + 1 } else { known_rgbs.len() } * mem::size_of::<u32>());
if freq_weighting {
self.buffer_known_rgbs_freqs.ensure_buffer(&self.device, buffer_known_rgbs_freqs_len);
}
let buffer_known_rgbs_bundle_map = self.device.map_memory(self.buffer_known_rgbs_bundle);
let known_rgbs_bundle: &mut [KnownRgbsPack] = slice::from_raw_parts_mut(buffer_known_rgbs_bundle_map, known_rgbs.len());
for ((rgb, lab, _), dest_lab) in known_rgbs.iter().zip(known_rgbs_bundle.iter_mut()) {
dest_lab = KnownRgbsPack {
rgb: rgb,
lab: lab,
};
}
self.buffer_known_rgbs_bundle.unmap(&self.device);
if freq_weighting {
let buffer_known_rgbs_freqs_map = self.device.map_memory(self.buffer_known_rgbs_freqs);
let known_rgbs_freqs: &mut [u32] = slice::from_raw_parts_mut(buffer_known_rgbs_freqs_map, buffer_known_rgbs_freqs_len / mem::size_of::<u32>());
if use_oneshot_driver {
for (rgb, _, freq) in known_rgbs {
known_rgbs_freqs[rgb] = freq;
}
} else {
for ((_, _, freq), dest_freq) in known_rgbs.iter().zip(known_rgbs_freqs.iter_mut()) {
dest_freq = freq;
}
}
self.buffer_known_rgbs_freqs.unmap(&self.device);
}
// ...
// posterise_grid_oneshot.kernel.hlsl.inc or posterise_grid.kernel.hlsl.inc
if use_oneshot_driver {
self.buffer_params_map.current_rgbs_len = known_rgbs.len();
let il = |len| if len <= 10_000 { -1 }
else if len <= 100_000 { 20 }
else { 10 };
let mut first = true;
for (orig_start, orig_next) in [(0, known_rgbs.len()),
(known_rgbs.len(), 0 )].iter().cycle() {
self.buffer_params_map.current_rgbs_start = orig_start;
self.buffer_params_map.current_rgbs_next = orig_next;
self.buffer_params_map.iter_limit = il(self.buffer_params_map.current_rgbs_len);
if first {
// memcpy(self.buffer_current_rgbs, self.buffer_known_rgbs, known_rgbs.len() * mem::size_of::<KnownRgbsPack>());
self.device.cmd_copy_buffer(self.cmd_buffer,
self.buffer_known_rgbs_bundle.buffer, self.buffer_current_rgbs_bundle.buffer,
&[vk::BufferCopy {
src_offset: 0,
dst_offset: 0,
size: known_rgbs.len() * mem::size_of::<KnownRgbsPack>(),
}]);
}
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE,
self.compute_pipeline[USEONESHOT + freq_weighting]);
self.device.cmd_dispatch(self.cmd_buffer, self.buffer_params_map.current_rgbs_len.div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
let still_to_do = self.buffer_params_map.current_rgbs_next - orig_next;
if still_to_do == 0 {
break;
}
println!("did {}/{} ({} steps); {} left",
self.buffer_params_map.current_rgbs_len - still_to_do,
self.buffer_params_map.current_rgbs_len,
self.buffer_params_map.iter_limit,
still_to_do);
self.buffer_params_map.current_rgbs_len = still_to_do;
first = false;
}
} else {
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE,
self.compute_pipeline[freq_weighting]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len().div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
}
// ... output copying
}
The actual value of [[10]] is roughly tuned to dispatch shaders that don't make effectively-zero progress and also don't take >8s (there's inherent per-dispatch/per-writeback overhead on one side of -1 and occupancy on the other). This is inherently slower (more indirection, more sparse) than not doing it, so only doing it when needed seems apt; >50'000 is as good of a threshold as any. (The corresponding shader.h diff is trivial.)
posterise_grid_oneshot.kernel.hlsl.inc differs little and predictably from its do-it-all counterpart:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(0)]] RWStructuredBuffer<float3> outputs; // HOST_VISIBLE
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
/* 3 */ KNOWN_RGBS_FREQS
[[vk::binding(4)]] StructuredBuffer<uint> groups_data; // DEVICE_LOCAL
[[vk::binding(5)]] RWStructuredBuffer<known_rgbs_pack> current_rgbs_bundle; // DEVICE_LOCAL
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint current_rgbs_start = params[0].current_rgbs_start;
const uint current_rgbs_len = params[0].current_rgbs_len;
const uint iter_limit = params[0].iter_limit;
const float radiussy_squared = params[0].radiussy_squared;
const float3 bbox_min = params[0].bbox_min;
const float3 bbox_range = params[0].bbox_range;
const uint3 grid_bothdirs = params[0].grid_bothdirs;
uint id = DTid.x;
if(id >= current_rgbs_len)
return;
id += current_rgbs_start;
known_rgbs_pack this = current_rgbs_bundle[id];
#define center this.lab
for(uint iter = 0; iter != iter_limit; ++iter) {
const uint3 gridpos = lab_to_gridpos(center, bbox_min, bbox_range);
const uint3 gridpos_from = gridpos - min(grid_bothdirs, gridpos);
const uint3 gridpos_to = min(gridpos + grid_bothdirs, GRID_SIZE - 1);
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint gx = gridpos_from.x; gx <= gridpos_to.x; ++gx)
for(uint gy = gridpos_from.y; gy <= gridpos_to.y; ++gy)
for(uint gz = gridpos_from.z; gz <= gridpos_to.z; ++gz) {
groupdesc_t group = params[0].group_ranges[gx][gy][gz];
for(; group.start_idx != group.end_idx; ++group.start_idx) {
const uint i = groups_data[group.start_idx];
INTERROGATED_LOAD
float3 tmp = interrogated_lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
#if !BRANCHLESS_ADD
if(matched)
#endif
{
FREQ_LOAD
newcenter_count += FREQ;
newcenter += FREQ * interrogated_lab;
}
}
}
newcenter /= newcenter_count;
bool same = newcenter == center;
if(same) {
outputs[this.rgb] = center;
return;
}
center = newcenter;
}
uint savein;
InterlockedAdd(params[0].current_rgbs_next, 1, savein);
current_rgbs_bundle[savein] = this;
}
#define KNOWN_RGBS_FREQS
#define BRANCHLESS_ADD 1
#define INTERROGATED_LOAD const float3 lab = known_rgbs_bundle[i].lab;
#define interrogated_lab lab
#define FREQ_LOAD
#define FREQ matched
#include "posterise_grid_oneshot.kernel.hlsl.inc"
posterise_grid_oneshot.mul.hlsl:
#define KNOWN_RGBS_FREQS [[vk::binding(3)]] StructuredBuffer<uint> known_rgbs_freqs; // DEVICE_LOCAL & HOST_VISIBLE
#define BRANCHLESS_ADD 0
#define INTERROGATED_LOAD const known_rgbs_pack interrogated = known_rgbs_bundle[i];
#define interrogated_lab interrogated.lab
#define FREQ_LOAD const uint freq = known_rgbs_freqs[interrogated.rgb];
#define FREQ freq
#include "posterise_grid_oneshot.kernel.hlsl.inc"
The expansion for [[palette]] is entirely unchanged:
const uint i = groups_data[group.start_idx];
const float3 lab = known_rgbs_bundle[i].lab;
float3 tmp = lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
newcenter_count += matched;
newcenter += matched * lab;
But [[*freq]] reads more data more indirectly:
const uint i = groups_data[group.start_idx];
const known_rgbs_pack interrogated = known_rgbs_bundle[i];
float3 tmp = interrogated.lab - center;
const bool matched = dot(tmp, tmp) <= radiussy_squared;
if(matched) {
const uint freq = known_rgbs_freqs[interrogated.rgb];
newcenter_count += freq;
newcenter += freq * interrogated.lab;
}
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) | ±σ |
|---|---|---|---|---|
| 5700 XT | 134.983ms | 142.337ms | 105.45% | 6.6ms/6.8ms |
| (speed-up vs previous) | -15.72% | -43.17% | 20.22 p.p. | |
| (speed-up vs base-line) | -4.76% | -19.75% | 13.20 p.p. | |
| iterations [[(pointsdone \operatorname{@} depth)]] | 2 [[((8726 \operatorname{@} q_{20}), (8029 \operatorname{@} \infty))]] | 2 [[((9892 \operatorname{@} q_{20}), (6863 \operatorname{@} \infty))]] | ||
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) | ±σ |
| 5700 XT | 136.594ms | 202.383ms | 148.16% | 6.6ms/10.4ms |
| (speed-up vs previous) | -18.34% | -39.76% | 22.71 p.p. | |
| (speed-up vs base-line) | -4.29% | -33.27% | 32.21 p.p. | |
| iterations [[(pointsdone \operatorname{@} depth)]] | 2 [[((8726 \operatorname{@} q_{20}), (8029 \operatorname{@} \infty))]] | |||
Previous and use_oneshot_driver = known_rgbs.len() > 50_000 are equivalent,
so this measures the minimum cost of the piece-meal shader.
As ever, d is equivalent except for measuring the relative cost of [[*freq]]:
the indirections really show — this is the first time that [[*freq]] is slower than [[palette]] in the non-degenerate case.
Becoming slower than base-line seems wrong some-how (largely on account of "how would it even be possible").
| (colours) | *16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 134.983ms | 6.090s | 110.051s | 6.6ms/21.5ms/1.958s |
| (speed-up vs previous) | -15.72% | -45.07% | — | |
| (speed-up vs base-line) | -4.37% | 7.82% | — | |
iterations[[(pointsdone \operatorname{@} depth)]] | 2[[(8726 \operatorname{@} q_{20}), (8029 \operatorname{@} \infty)]] | 20[[(3439 \operatorname{@} q_{20}), (4585 \operatorname{@} q_{40}), (4990 \operatorname{@} q_{60}), (7237 \operatorname{@} q_{80}), (8241 \operatorname{@} q_{100}), (1893 \operatorname{@} q_{120}), (1537 \operatorname{@} q_{140}), (1434 \operatorname{@} q_{160}), (1165 \operatorname{@} q_{180}), (1606 \operatorname{@} q_{200}), (1593 \operatorname{@} q_{220}), (2736 \operatorname{@} q_{240}), (4634 \operatorname{@} q_{260}), (7876 \operatorname{@} q_{280}), (7448 \operatorname{@} q_{300}), (4920 \operatorname{@} q_{320}), (4170 \operatorname{@} q_{340}), (3074 \operatorname{@} q_{360}), (2309 \operatorname{@} q_{380}), (9973 \operatorname{@} \infty)]] | 63[[(409 \operatorname{@} q_{10}), (536 \operatorname{@} q_{20}), (489 \operatorname{@} q_{30}), (481 \operatorname{@} q_{40}), (544 \operatorname{@} q_{50}), (678 \operatorname{@} q_{60}), (907 \operatorname{@} q_{70}), (1251 \operatorname{@} q_{80}), (1929 \operatorname{@} q_{90}), (2851 \operatorname{@} q_{100}), (4193 \operatorname{@} q_{110}), (5704 \operatorname{@} q_{120}), (4411 \operatorname{@} q_{130}), (2533 \operatorname{@} q_{140}), (2646 \operatorname{@} q_{150}), (2672 \operatorname{@} q_{160}), (2617 \operatorname{@} q_{170}), (2507 \operatorname{@} q_{180}), (2516 \operatorname{@} q_{190}), (2675 \operatorname{@} q_{200}), (2591 \operatorname{@} q_{210}), (2588 \operatorname{@} q_{220}), (2597 \operatorname{@} q_{230}), (2768 \operatorname{@} q_{240}), (2961 \operatorname{@} q_{250}), (3020 \operatorname{@} q_{260}), (3059 \operatorname{@} q_{270}), (3049 \operatorname{@} q_{280}), (3090 \operatorname{@} q_{290}), (3296 \operatorname{@} q_{300}), (3187 \operatorname{@} q_{310}), (3256 \operatorname{@} q_{320}), (3291 \operatorname{@} q_{330}), (3275 \operatorname{@} q_{340}), (3615 \operatorname{@} q_{350}), (3757 \operatorname{@} q_{360}), (3871 \operatorname{@} q_{370}), (3849 \operatorname{@} q_{380}), (3836 \operatorname{@} q_{390}), (3705 \operatorname{@} q_{400}), (3818 \operatorname{@} q_{410}), (3911 \operatorname{@} q_{420}), (4062 \operatorname{@} q_{430}), (4193 \operatorname{@} q_{440}), (4413 \operatorname{@} q_{450}), (4413 \operatorname{@} q_{460}), (4387 \operatorname{@} q_{470}), (4500 \operatorname{@} q_{480}), (4547 \operatorname{@} q_{490}), (9053 \operatorname{@} q_{510}), (9153 \operatorname{@} q_{530}), (9378 \operatorname{@} q_{550}), (8867 \operatorname{@} q_{570}), (8828 \operatorname{@} q_{590}), (8023 \operatorname{@} q_{610}), (7043 \operatorname{@} q_{630}), (6459 \operatorname{@} q_{650}), (5885 \operatorname{@} q_{670}), (5115 \operatorname{@} q_{690}), (4191 \operatorname{@} q_{710}), (3501 \operatorname{@} q_{730}), (2921 \operatorname{@} q_{750}), (9060 \operatorname{@} \infty)]] | |
| 5700 XT, [[*freq]] | 142.337ms | 6.687s | 53.222s | 6.8ms/59.9ms/1.702s |
| (speed-up vs previous) | -43.17% | -103.48% | — | |
| (speed-up vs base-line) | -17.53% | -53.49% | — | |
iterations[[(pointsdone \operatorname{@} depth)]] | 2[[(9892 \operatorname{@} q_{20}), (6863 \operatorname{@} \infty)]] | 12[[( 4698 \operatorname{@} q_{20}), ( 6368 \operatorname{@} q_{40}), (11911 \operatorname{@} q_{60}), (12558 \operatorname{@} q_{80}), ( 7092 \operatorname{@} q_{100}), (11538 \operatorname{@} q_{120}), ( 8300 \operatorname{@} q_{140}), ( 5246 \operatorname{@} q_{160}), ( 3911 \operatorname{@} q_{180}), ( 2755 \operatorname{@} q_{200}), ( 2384 \operatorname{@} q_{220}), ( 8099 \operatorname{@} \infty)]] | 23[[(1853 \operatorname{@} q_{10}), (11458 \operatorname{@} q_{20}), (8918 \operatorname{@} q_{30}), (7158 \operatorname{@} q_{40}), (6140 \operatorname{@} q_{50}), (7593 \operatorname{@} q_{60}), (10377 \operatorname{@} q_{70}), (13072 \operatorname{@} q_{80}), (15944 \operatorname{@} q_{90}), (18398 \operatorname{@} q_{100}), (16329 \operatorname{@} q_{110}), (16083 \operatorname{@} q_{120}), (15680 \operatorname{@} q_{130}), (23235 \operatorname{@} q_{150}), (15649 \operatorname{@} q_{170}), (11954 \operatorname{@} q_{190}), (9276 \operatorname{@} q_{210}), (6745 \operatorname{@} q_{230}), (5624 \operatorname{@} q_{250}), (4809 \operatorname{@} q_{270}), (4091 \operatorname{@} q_{290}), (2944 \operatorname{@} q_{310}), (9601 \operatorname{@} \infty)]] | |
| (colours) | *27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 2.773s | 123.019s | 49.478s | 454.9ms/1.77s/973ms |
| (speed-up vs previous) | -46.61% | — | — | |
| (speed-up vs base-line) | -90.46% | — | — | |
iterations[[(pointsdone \operatorname{@} depth)]] | 10[[( 1435 \operatorname{@} q_{20}), ( 2011 \operatorname{@} q_{40}), ( 3731 \operatorname{@} q_{60}), ( 3481 \operatorname{@} q_{80}), ( 2988 \operatorname{@} q_{100}), ( 2211 \operatorname{@} q_{120}), ( 589 \operatorname{@} q_{140}), ( 629 \operatorname{@} q_{160}), ( 805 \operatorname{@} q_{180}), ( 9988 \operatorname{@} \infty)]] | 32[[(2863 \operatorname{@} q_{10}), (2399 \operatorname{@} q_{20}), (4471 \operatorname{@} q_{30}), (6288 \operatorname{@} q_{40}), (10097 \operatorname{@} q_{50}), (14279 \operatorname{@} q_{60}), (15496 \operatorname{@} q_{70}), (19285 \operatorname{@} q_{80}), (17463 \operatorname{@} q_{90}), (11674 \operatorname{@} q_{100}), (10639 \operatorname{@} q_{110}), (10127 \operatorname{@} q_{120}), (11113 \operatorname{@} q_{130}), (13380 \operatorname{@} q_{140}), (15469 \operatorname{@} q_{150}), (16069 \operatorname{@} q_{160}), (14800 \operatorname{@} q_{170}), (11883 \operatorname{@} q_{180}), (9652 \operatorname{@} q_{190}), (8774 \operatorname{@} q_{200}), (8787 \operatorname{@} q_{210}), (17262 \operatorname{@} q_{230}), (13791 \operatorname{@} q_{250}), (12693 \operatorname{@} q_{270}), (11791 \operatorname{@} q_{290}), (9938 \operatorname{@} q_{310}), (7493 \operatorname{@} q_{330}), (4933 \operatorname{@} q_{350}), (3457 \operatorname{@} q_{370}), (2139 \operatorname{@} q_{390}), (1250 \operatorname{@} q_{410}), (8911 \operatorname{@} \infty)]] | 16[[(12380 \operatorname{@} q_{10}), (80853 \operatorname{@} q_{20}), (174244 \operatorname{@} q_{30}), (186416 \operatorname{@} q_{40}), (151358 \operatorname{@} q_{50}), (118824 \operatorname{@} q_{60}), (87645 \operatorname{@} q_{70}), (72871 \operatorname{@} q_{80}), (56003 \operatorname{@} q_{90}), (38613 \operatorname{@} q_{100}), (31674 \operatorname{@} q_{110}), (38589 \operatorname{@} q_{130}), (22957 \operatorname{@} q_{150}), (12058 \operatorname{@} q_{170}), (8975 \operatorname{@} q_{190}), (9887 \operatorname{@} \infty)]] | |
| 5700 XT, [[*freq]] | 746.454ms | 77.749s | 24.291s | 17.3ms/829ms/1.062s |
| (speed-up vs previous) | -31.55% | — | — | |
| (speed-up vs base-line) | -99.89% | — | — | |
iterations[[(pointsdone \operatorname{@} depth)]] | 3[[(17216 \operatorname{@} q_{20}), ( 7467 \operatorname{@} q_{40}), ( 3185 \operatorname{@} \infty)]] | 63[[(317 \operatorname{@} q_{10}), (362 \operatorname{@} q_{20}), (878 \operatorname{@} q_{30}), (1789 \operatorname{@} q_{40}), (2419 \operatorname{@} q_{50}), (3814 \operatorname{@} q_{60}), (3577 \operatorname{@} q_{70}), (2930 \operatorname{@} q_{80}), (3392 \operatorname{@} q_{90}), (3645 \operatorname{@} q_{100}), (3472 \operatorname{@} q_{110}), (4022 \operatorname{@} q_{120}), (4420 \operatorname{@} q_{130}), (4944 \operatorname{@} q_{140}), (6067 \operatorname{@} q_{150}), (8302 \operatorname{@} q_{160}), (6410 \operatorname{@} q_{170}), (4369 \operatorname{@} q_{180}), (4688 \operatorname{@} q_{190}), (4601 \operatorname{@} q_{200}), (4590 \operatorname{@} q_{210}), (4849 \operatorname{@} q_{220}), (4877 \operatorname{@} q_{230}), (4993 \operatorname{@} q_{240}), (5327 \operatorname{@} q_{250}), (5790 \operatorname{@} q_{260}), (6589 \operatorname{@} q_{270}), (7088 \operatorname{@} q_{280}), (7359 \operatorname{@} q_{290}), (7199 \operatorname{@} q_{300}), (6704 \operatorname{@} q_{310}), (6672 \operatorname{@} q_{320}), (6604 \operatorname{@} q_{330}), (6554 \operatorname{@} q_{340}), (6509 \operatorname{@} q_{350}), (6431 \operatorname{@} q_{360}), (6327 \operatorname{@} q_{370}), (5989 \operatorname{@} q_{380}), (5642 \operatorname{@} q_{390}), (5447 \operatorname{@} q_{400}), (5105 \operatorname{@} q_{410}), (4979 \operatorname{@} q_{420}), (4806 \operatorname{@} q_{430}), (4710 \operatorname{@} q_{440}), (4574 \operatorname{@} q_{450}), (4581 \operatorname{@} q_{460}), (4327 \operatorname{@} q_{470}), (8770 \operatorname{@} q_{490}), (8484 \operatorname{@} q_{510}), (8201 \operatorname{@} q_{530}), (7705 \operatorname{@} q_{550}), (7465 \operatorname{@} q_{570}), (7143 \operatorname{@} q_{590}), (6636 \operatorname{@} q_{610}), (6336 \operatorname{@} q_{630}), (5917 \operatorname{@} q_{650}), (5208 \operatorname{@} q_{670}), (4925 \operatorname{@} q_{690}), (4257 \operatorname{@} q_{710}), (3813 \operatorname{@} q_{730}), (3644 \operatorname{@} q_{750}), (2455 \operatorname{@} q_{770}), (8667 \operatorname{@} \infty)]] | 7[[(269906 \operatorname{@} q_{10}), (475001 \operatorname{@} q_{20}), (202825 \operatorname{@} q_{30}), (82171 \operatorname{@} q_{40}), (50097 \operatorname{@} q_{60}), (16122 \operatorname{@} q_{80}), (7225 \operatorname{@} \infty)]] | |
| *: slow-down doesn't apply (and subsequent measurement comparisons will ignore it) —: didn't complete before | ||||
The slow-down is even more surprising here, but this is why images with few colours are not beholden to the new shader. Images with many complete for the first time, and this explains why 328'666 is so much slower than 1'103'347 — a maximum observed iteration depth of [[q_{410}]]/[[q_{770}]] beats [[q_{190}]]/[[q_{80}]].
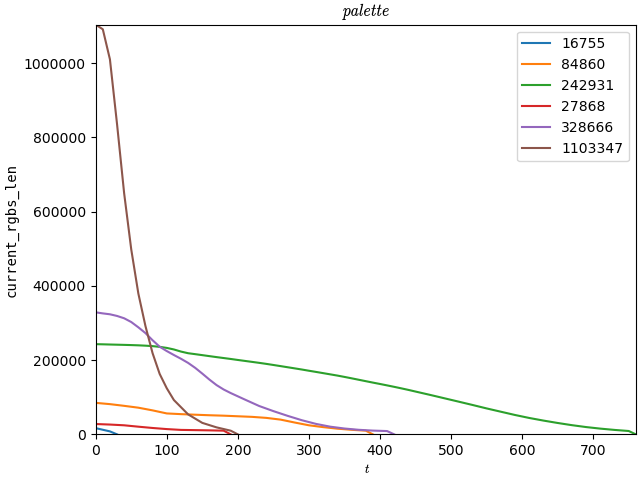
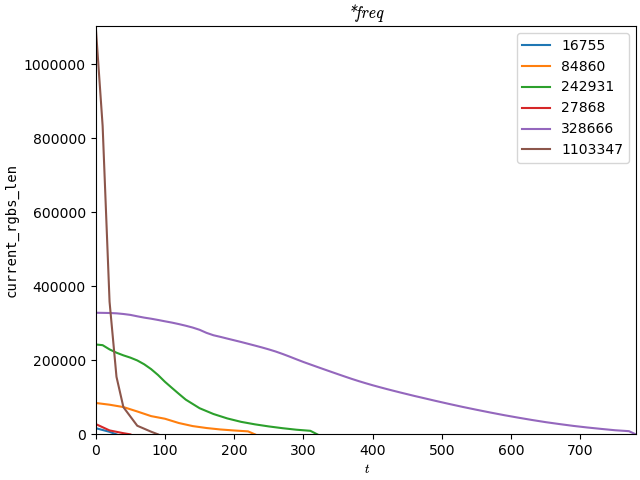
# straight up "bussing it" and by "it", haha, well. let's justr say. My rgbs.
It's convenient to replace the CPU implementation isocallingconventionally but it's also a little silly and goofy to run the [[p]]/[[p']] transformations on the CPU when a dedicated FPU is available. known_rgbs work items can be thinned to just [[({\color{var(--r)}r\color{initial}}{\color{var(--r)}r\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--g)}g\color{initial}}{\color{var(--b)}b\color{initial}}{\color{var(--b)}b\color{initial}}_{16}, \text{multiplicity of}\ \color{var(--r)}r\color{initial},\color{var(--g)}g\color{initial},\color{var(--b)}b\color{initial})]], and the returned outputs [[f]] mapping reduced from [[C \to P]] directly to [[C \to C]], so the whole RgbStuffedInLab dance can likewise go the way of the dinosaur:
let mut outputs = [[u8; 3]; 0xFFFFFF + 1]; // was [[f32; 3]; ...]
// ...
let known_rgbs: Vec<(u32, u32)> = frequencies.iter() // was Vec<(u32, Lab, u32)>
.enumerate()
.filter(|(rgb, freq)| freq != 0)
.collect();
This also allows reducing the outputs mapping from an array of (float3, padding primitive)) to uint, quartering the allocation (this matches the ranges used with outputs as a staging buffer), and turns the outputs copy into a byte swizzle:
pub struct PosteriseGpu {
// ...
buffer_outputs: BufferBundle, // [[vk::binding(0)]] SB<uint> outputs; [HOST_VISIBLE]
buffer_outputs_map: &'static mut [u32; 0xFFFFFF + 1],
// ...
}
fn PosteriseGpu::susmit(&mut self, known_rgbs: &[(u32, u32)], radiussy: f32, freq_weighting: bool, outputs: &mut [[u8; 3]; 0xFFFFFF + 1]) {
// ...
let buffer_known_rgbs_bundle_map = self.device.map_memory(self.buffer_known_rgbs_bundle);
let known_rgbs_bundle: &mut [KnownRgbsPack] = slice::from_raw_parts_mut(buffer_known_rgbs_bundle_map, known_rgbs.len());
for ((known, _), bundle) in known_rgbs.iter().zip(known_rgbs_bundle.iter_mut()) {
bundle.rgb = known;
}
// ... known_rgbs_freqs setup
// expand_rgb.hlsl
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[EXPAND_RGB]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.len().div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
// ... everything through posterise_grid.kernel.hlsl.inc/posterise_grid_oneshot.kernel.hlsl.inc
for (rgb, _) in known_rgbs {
let out = self.buffer_outputs_map[rgb];
outputs[rgb][0] = (out >> 16); // [[\color{var(--r)}r\color{initial}]]
outputs[rgb][1] = (out >> 8) & 0xFF; // [[\color{var(--g)}g\color{initial}]]
outputs[rgb][2] = (out >> 0) & 0xFF; // [[\color{var(--b)}b\color{initial}]]
}
}
where expand_rgb.hlsl is a trivial [[p \circ I]]:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] RWStructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL & HOST_VISIBLE
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
known_rgbs_bundle[id].lab =
linear_srgb_to_oklab(unpack_rgb_to_r_g_b(known_rgbs_bundle[id].rgb));
}
[[p^{-1}]] distributed across the kernels:
[[vk::binding(0)]] RWStructuredBuffer<uint> outputs; // HOST_VISIBLE
// posterise_grid_oneshot.kernel.hlsl.inc
if(same) {
outputs[this.rgb] = pack_r_g_b_to_rgb(oklab_to_linear_srgb(center));
return;
}
// posterise_grid.kernel.hlsl.inc
}
outputs[this.rgb] = pack_r_g_b_to_rgb(oklab_to_linear_srgb(center));
}
and predictable (un)packing in shader.h:
float3 unpack_rgb_to_r_g_b(uint rgb) {
return uint3(rgb >> 16, (rgb >> 8) & 0xFF, (rgb >> 0) & 0xFF) / float(0xFF);
}
uint pack_r_g_b_to_rgb(float3 r_g_b) {
uint3 rgb = uint3(round(r_g_b * 0xFF));
return (rgb.r << 16) | (rgb.g << 8) | (rgb.b << 0);
}
| (colours) | 16'755 | 1'103'347 | ±σ |
|---|---|---|---|
| known_rgbs before | 14.680ms | 210.771ms | 339µs/21.17ms |
| dest_lab = KnownRgbsPack { rgb, lab } | 72.793µs | 5.397ms | 7.87µs/168.2µs |
| known_rgbs after | 12.115ms | 28.952ms | 1.04ms/848µs |
| bundle.rgb = known | 141.841µs | 10.076ms | 11.67µs/237.5µs |
| expand_rgb.hlsl | 129.086µs | 200.058µs | 621µs/452µs |
| (speed-up) | 16.04% | 81.85% |
this is fixed analysis cost for an image (and, interestingly, a quarter of the bytes in known_rgbs_bundle is ~2× slower; I'm assuming it induces a cache-line read/modify/write instead of a full write); the following is paid for each computation/parameter change; RgbStuffedInLab is considered to be distributed across each final [[f]] computation on the GPU, thus becoming immaterial:
| (colours) | 16'755, [[palette]] | 1'103'347, [[palette]] | ±σ |
|---|---|---|---|
| outputs[…].l = buffer_outputs_map[…][0] | 2.471ms | 162.519ms | 303µs/234µs |
| RgbStuffedInLab | 1.405ms | 53.867ms | 57.66µs/797.24ms |
| outputs[…][0] = out >> 16 | 1.2913ms | 82.727ms | 4.49ms/2.12ms |
| (speed-up) | 66.69% | 61.77% |
For 16'755 this is ~16% → ~12% of overall runtime; for 1'103'347 — ~0.75% → ~0.22%. Not meaningless.

Most of this is fixed per image and running it each time is wasteful, so it's time for
# our very own Enron scandal.
It also makes more sense to split known_rgbs first:
let mut known_rgbs_rgbs: Vec<u32> = vec![];
let mut known_rgbs_freqs: Vec<u32> = vec![];
for (rgb, freq) in frequencies.iter().enumerate().filter(|(_, f)| f != 0) {
known_rgbs_rgbs.push(rgb);
known_rgbs_freqs.push(freq);
}
posterise_gpu.measure(&known_rgbs_rgbs, &known_rgbs_freqs);
And the analysis pre-computation step enforced thusly:
pub struct PosteriseGpu {
// ...
use_oneshot_driver: bool,
}
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
assert!(known_rgbs_rgbs.len() == known_rgbs_freqs.len())
let known_rgbs = known_rgbs_rgbs.len();
self.use_oneshot_driver = known_rgbs > 50_000;
// everything previously in susmit()...
// No longer predicated on freq_weighting (must accommodate either):
self.buffer_known_rgbs_freqs.ensure_buffer(&self.device, buffer_known_rgbs_freqs_len);
for (rgb, bundle) in known_rgbs_rgbs.iter().zip(known_rgbs_bundle.iter_mut()) {
bundle.rgb = rgb;
}
// No longer predicated on freq_weighting (must accommodate either):
let known_rgbs_freqs_out = std::slice::from_raw_parts_mut(known_rgbs_freqs_buffer_map as *mut u32, 0xFFFFFF + 1);
if self.use_oneshot_driver {
for (rgb, freq) in known_rgbs_rgbs.iter().zip(known_rgbs_freqs) {
known_rgbs_freqs_out[rgb] = freq;
}
} else {
// memcpy(known_rgbs_freqs_buffer_map, known_rgbs_freqs, known_rgbs * sizeof(u32))
ptr::copy_nonoverlapping(known_rgbs_freqs.as_ptr(), known_rgbs_freqs_buffer_map, known_rgbs);
}
// ...up to and including assign_cell.hlsl
}
fn PosteriseGpu::susmit(&mut self, known_rgbs_rgbs: &[u32], radiussy: f32, freq_weighting: bool, outputs: &mut [[u8; 3]; 0xFFFFFF + 1]) {
{
self.buffer_params_map.radiussy_squared = radiussy * radiussy;
self.buffer_params_map.grid_bothdirs = /* ... */;
}
// posterise_grid.kernel.hlsl.inc/posterise_grid_oneshot.kernel.hlsl.inc
// for rgb in known_rgbs_rgbs { outputs[rgb] = ...; }
}
copying the frequency data is simplified by the new layout, but must happen every time. Doesn't really matter
| (colours) | 16'755 | 1'103'347 | ±σ |
|---|---|---|---|
| known_rgbs_{rgbs,freqs} | 14.675ms | 27.954ms | 1.04ms/1.92ms |
| (speed-up) | -21.13% | 3.45% |
this is, practically, a wash (σ is like 6%); overall re-accounting like this remits
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, measure() | 8.095ms | 17.478ms | 33.629ms | 918µs/4.27ms/2.58ms |
| (of previous, [[palette]]) | 7.01% | 0.29% | 0.03% | |
| (of previous, [[*freq]]) | 5.59% | 0.26% | 0.06% | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, measure() | 9.298ms | 45.637ms | 140.834ms | 948µs/5ms/24.82ms |
| (of previous, [[palette]]) | 0.49% | 0.04% | 0.28% | |
| (of previous, [[*freq]]) | 1.64% | 0.06% | 0.58% |
(though, of course, the [[palette]] path now also copies frequency data for 40µs-20ms which it didn't before).
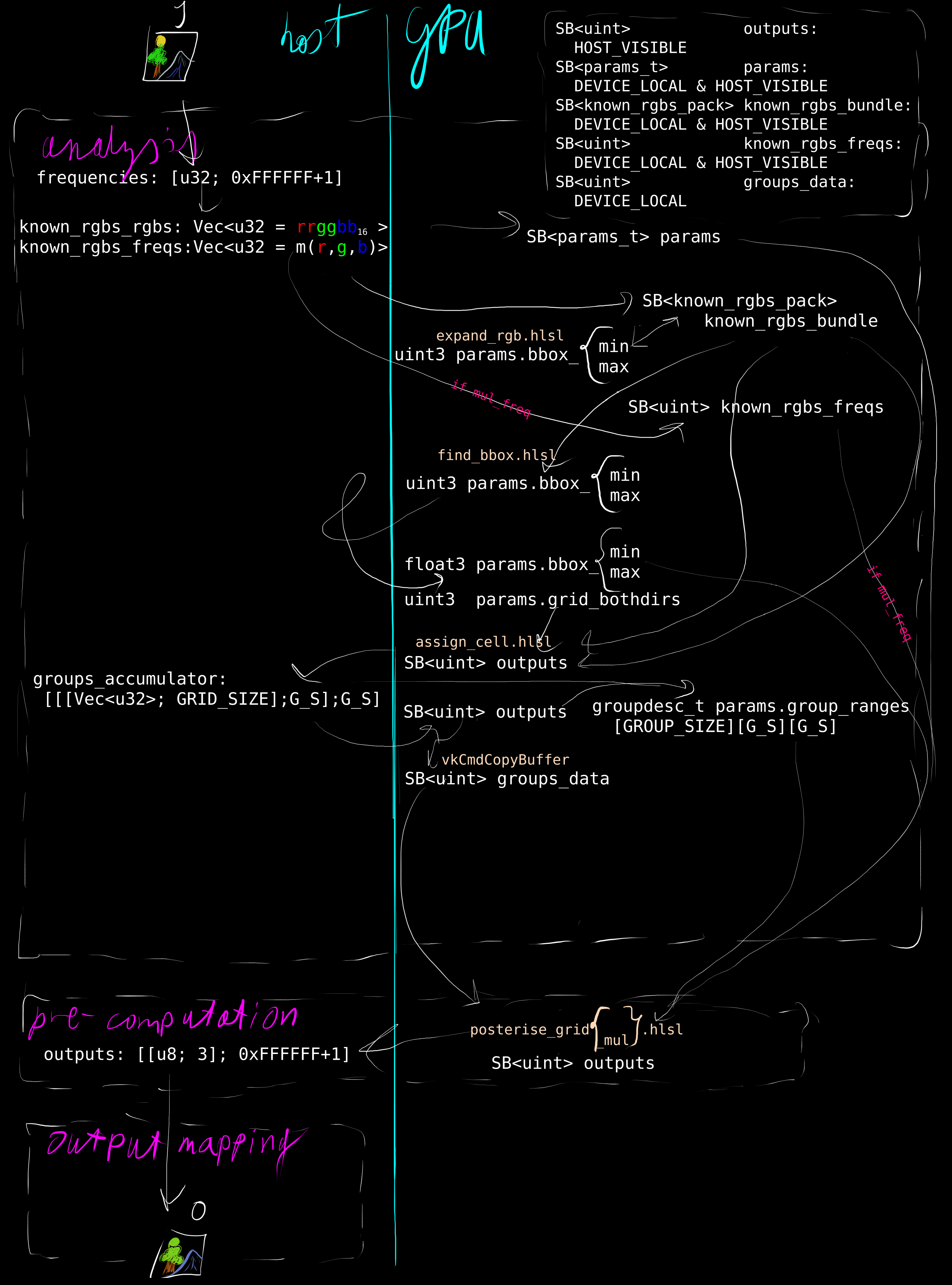
# Do NOT tell americans about your allocations. Worst mistake of my life.
The allocations in question, of course, being known_rgbs_bundle and known_rgbs_freqs, both uploaded to precious DEVICE_LOCAL & HOST_VISIBLE memory directly. These are write-only for the host, and writing only part of the former was slower anyway. Thus, the driver:
const DISTRIBUTE_ONESHOT_FREQS: usize = EXPAND_RGB + 1;
pub struct PosteriseGpu {
// ...
buffer_known_rgbs_bundle: BufferBundle, // [[vk::binding(2)]] SB<known_rgbs_pack> known_rgbs_bundle; [DEVICE_LOCAL]
buffer_known_rgbs_freqs: BufferBundle, // [[vk::binding(3)]] SB<uint> known_rgbs_freqs; [DEVICE_LOCAL]
// ...
}
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
// vk::BufferUsageFlags::STORAGE_BUFFER | ::TRANSFER_SRC ⬎ ⬐ ::TRANSFER_DST
ret.buffer_known_rgbs_bundle = BufferBundle(private_memory_type_index, true, false);
ret.buffer_known_rgbs_freqs = BufferBundle(private_memory_type_index, false, true); // false, false
// ...
}
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ... ensure_buffer() ...
// expand_rgb.hlsl
// memcpy(buffer_outputs_map, known_rgbs_freqs, known_rgbs * sizeof(u32))
ptr::copy_nonoverlapping(known_rgbs_rgbs.as_ptr(), self.buffer_outputs_map.as_ptr(), known_rgbs);
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[EXPAND_RGB]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.div_ceil(64), 1, 1);
self.submit_buffer(self.cmd_buffer);
// memcpy or distribute_oneshot_freqs.hlsl
// memcpy(buffer_outputs_map, known_rgbs_freqs, known_rgbs * sizeof(u32))
ptr::copy_nonoverlapping(known_rgbs_freqs.as_ptr(), self.buffer_outputs_map.as_ptr(), known_rgbs);
if self.use_oneshot_driver {
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE, self.compute_pipeline[DISTRIBUTE_ONESHOT_FREQS]);
self.device.cmd_dispatch(self.cmd_buffer, known_rgbs.div_ceil(64), 1, 1);
} else {
// memcpy(buffer_known_rgbs_freqs, buffer_outputs, buffer_known_rgbs_freqs_len)
self.device.cmd_copy_buffer(self.cmd_buffer, self.buffer_outputs.buffer, self.buffer_known_rgbs_freqs.buffer,
&[vk::BufferCopy {
src_offset: 0,
dst_offset: 0,
size: buffer_known_rgbs_freqs_len,
}]);
}
self.submit_buffer(self.cmd_buffer);
// find_bbox.hlsl ...
}
expand_rgb.hlsl
needs to populate the whole bundle instead of just updating .lab:
known_rgbs_pack bundle;
bundle.rgb = outputs[id];
bundle.lab = linear_srgb_to_oklab(unpack_rgb_to_r_g_b(bundle.rgb));
known_rgbs_bundle[id] = bundle;
and the new
distribute_oneshot_freqs.hlsl
replaces the known_rgbs_freqs_out[rgb] = freq loop:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(0)]] StructuredBuffer<uint> outputs; // HOST_VISIBLE
[[vk::binding(1)]] StructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL
[[vk::binding(3)]] RWStructuredBuffer<uint> known_rgbs_freqs; // DEVICE_LOCAL
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
known_rgbs_freqs[known_rgbs_bundle[id].rgb] = outputs[id];
}
| (colours) | 16'755 | 1'103'347 | ±σ |
|---|---|---|---|
| host → known_rgbs_{rgbs,freqs} | 226µs | 29.529ms | 124µs/62.8µs |
| (proportion of measure()) | 2.8% | 21% | |
| memcpy or distribute_oneshot_freqs.hlsl | 130µs | 770µs | 62.8µs/21µs |
| (speed-up, 5700 XT) | 42.72% | 38.347× | |
| (proportion of measure()) | 1.6% | 0.6% |
This leaves just params (constant [[G^3 \operatorname{sizeof}(\texttt{(uint, uint)}) + \varepsilon \approx 8\text{MB} \approx 3\%]]) in DEVICE_LOCAL & HOST_VISIBLE,
freeing [[\overline{Set(I)}(\operatorname{sizeof}(\texttt{struct known_rgbs_pack}) + \operatorname{sizeof}(\texttt{uint})) = \overline{Set(I)} \cdot 20\text{B}]]
([[\in [335\text{kB}, 22\text{MB}] \approx [0.13\%, 8.6\%]]] in test data;
theoretical maximum [[320\text{MiB} = 125\%]]).

# You do not under any circumstances have to hand it to Scott Adams
The [start, end) pairs in the groups_data half of [[h]] are laid out in natural axis order, i.e. a linear search through group_ranges[outermost][middle][innermost] corresponds to a linear search through groups_data; if we, for convenience, say that each cell contains exactly one point, we then know that [[\forall x,y,z \in \bar{G} : \texttt{group_ranges}[x][y][z] = G^2x + Gy + z]] and cast the traversal order back onto the the grid thusly
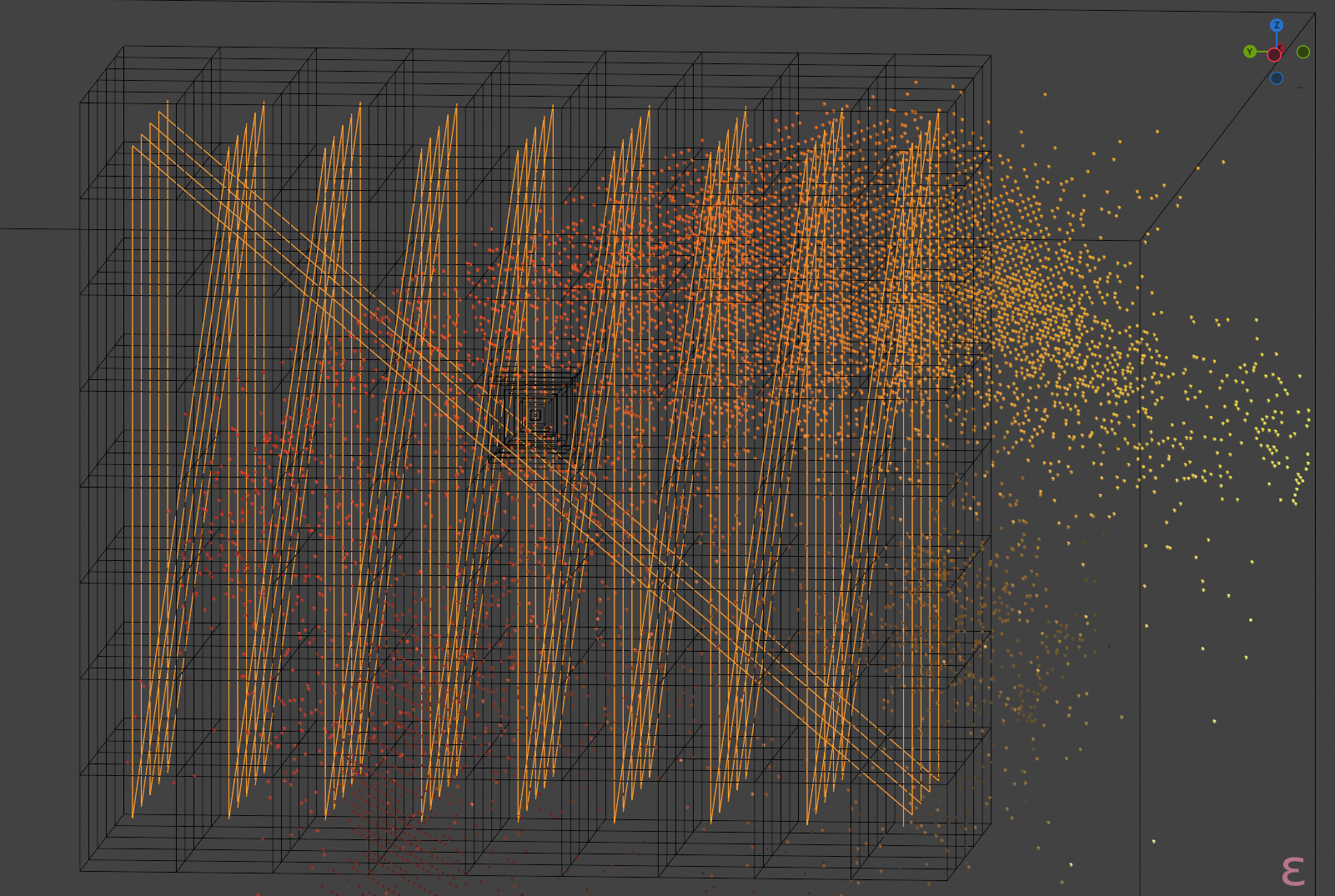
where a discontinuity (long diagonal line) occurs after every extremum; thus, locality is low, and on the CPU one'd expect this to have a significant effect on iteration speed. The ideal iteration order [[l]] would, in all possible cases, maximally preserve locality (such that geometrically close cells' data is memorically close in groups_data): [[\forall x,y,z \in \bar{G} : \texttt{group_ranges}[x][y][z] = l(G^2x + Gy + z)]].
The Hilbert curve is the canonical solution for this, and googling "hilbert curve 3d" yields Algorithms for Encoding and Decoding 3D Hilbert Orderings, David Walker, August 2023 with the world's most obtuse pseudocode. Unfortunately, Hilbert curves are only defined for square/cubic domains with side length [[2^n]], which [[G=100]] is not. Maybe [[G \in \{64, 128\}]] could work:
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...assign_cell.hlsl, grouping
// copying
let mut known_rgbs_groups: *mut u32 = self.buffer_outputs_map.as_ptr() as _;
let mut cur = 0;
let mut dump = |gr_z: &mut GroupDesc, ga_z: &Vec<u32>|
if ga_z.len() != 0 {
let start = cur;
// memcpy(known_rgbs_groups, ga_z.as_ptr(), ga_z.len())
known_rgbs_groups.copy_from_nonoverlapping(ga_z.as_ptr(), ga_z.len());
cur += ga_z.len();
known_rgbs_groups = known_rgbs_groups.add(ga_z.len());
*gr_z = GroupDesc {
start_idx: start,
end_idx: cur,
};
};
for i in 0..GRID_SIZE * GRID_SIZE * GRID_SIZE {
let (x, y, z) = decodeh(i);
dump(&mut self.buffer_params_map.group_ranges[x][y][z],
& self.groups_accumulator [x][y][z])
}
assert!(cur == known_rgbs.len());
// memcpy(self.buffer_groups_data, self.buffer_outputs, known_rgbs * mem::size_of::<u32>())...
}
However, Generalized Hilbert ("gilbert") space-filling curve for rectangular domains of arbitrary (non-power of two) sizes., Jakub Červený, 2019 may, after a quick port, allow using a more optimal [[G]]:
| (colours) | 16'755 | 84'860 | 242'931 | ||
|---|---|---|---|---|---|
| straight | 643 | 94.98ms | 6.01s | 97.67s | |
| straight | 803 | 128.99ms | 6.87s | 83.75s | |
| straight | 903 | 126.06ms | 6.98s | 128.76s | |
| straight | 1003 | 120.33ms | 6.81s | 119.00s | |
| straight | 1283 | 162.10ms | 10.74s | 129.18s | |
| gilbert | 803 | 130.03ms | 6.80s | 96.04s | |
| gilbert | 903 | 125.51ms | 6.80s | 107.87s | |
| gilbert | 1003 | 121.04ms | 6.71s | 112.36s | |
| hilbert | 643 | 94.65ms | 6.04s | 101.08s | |
| hilbert | 1283 | 157.09ms | 10.52s | 123.02s | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ||
| straight | 643 | 1.21s | 129.69s | — | (driver timeout) |
| straight | 803 | 1.27s | 138.32s | 66.48s | (came within 200ms of a driver timeout) |
| straight | 903 | 1.30s | 143.71s | 52.33s | |
| straight | 1003 | 1.78s | 142.43s | 49.49s | |
| straight | 1283 | 2.11s | 190.65s | 67.33s | |
| gilbert | 803 | 1.27s | 148.03s | — | (driver timeout) |
| gilbert | 903 | 1.26s | 139.38s | 56.16s | |
| gilbert | 1003 | 1.75s | 131.85s | 48.74s | |
| hilbert | 643 | 1.23s | 130.17s | — | (driver timeout) |
| hilbert | 1283 | 2.16s | 189.07s | 67.86s | (driver timeout the first time) |
| (Measurement multiplicity diminished.) | |||||
[[G=100]] gilbert seems, like, kinda the best. Maybe. A little bit? This sucks. Just generating all the values of decodeh ([[l : {\mkern 1.5mu\overline{\mkern-1.5mu{G^3}\mkern-1.5mu}\mkern 1.5mu} \to \bar{G}^3]] takes 3341.45ms ± 208ms) which is untenable to do live but it's constant, so may be pre-computed in build.rs, conveniently in parallel to the shaders building (but only if need be since they don't take that long):
include!("ext/gilbert/ports/gilbert.rs");
fn main() {
let grid_size = fs::read_to_string("src/shader.h").lines()
.find(|l| l.contains("#define GRID_SIZE")).split_whitespace().last();
// ... glslc
let out_dir = Path::new(&env::var_os("OUT_DIR"));
let grid_size_rs = out_dir.join("grid_size.rs");
if grid_size != fs::read_to_string(grid_size_rs).unwrap_or("".to_string()) {
fs::write(grid_size_rs, grid_size);
let grid_size = grid_size.parse();
let mut grid_gilbert = File::create(out_dir.join("grid_gilbert.xyz"));
for i in 0..grid_size * grid_size * grid_size {
let (x, y, z) = gilbert::d2xyz(i, (grid_size, grid_size, grid_size));
grid_gilbert.write_all(&[x, y, z]);
}
}
// ... glslc collexion
}
Why not generate [(1, 2, 3), (4, 5, 6), …] and include!("…/grid_gilbert.rs")? Because that include! would be of a million-element array which takes ~40s (and implies like three compiler bugs). Including [[3\text{MB}]] directly is functionally instant:
static GRID_GILBERT: &[(u8, u8, u8)] = include_typed!((u8, u8, u8), concat!(env!("OUT_DIR"), "/grid_gilbert.xyz"));
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...
assert!(mem::size_of::<(u8, u8, u8)>() == 3);
assert!(GRID_GILBERT.len() == GRID_SIZE * GRID_SIZE * GRID_SIZE);
for (x, y, z) in GRID_GILBERT {
dump(&mut self.buffer_params_map.group_ranges[x][y][z],
& self.groups_accumulator [x][y][z])
}
// ...
}
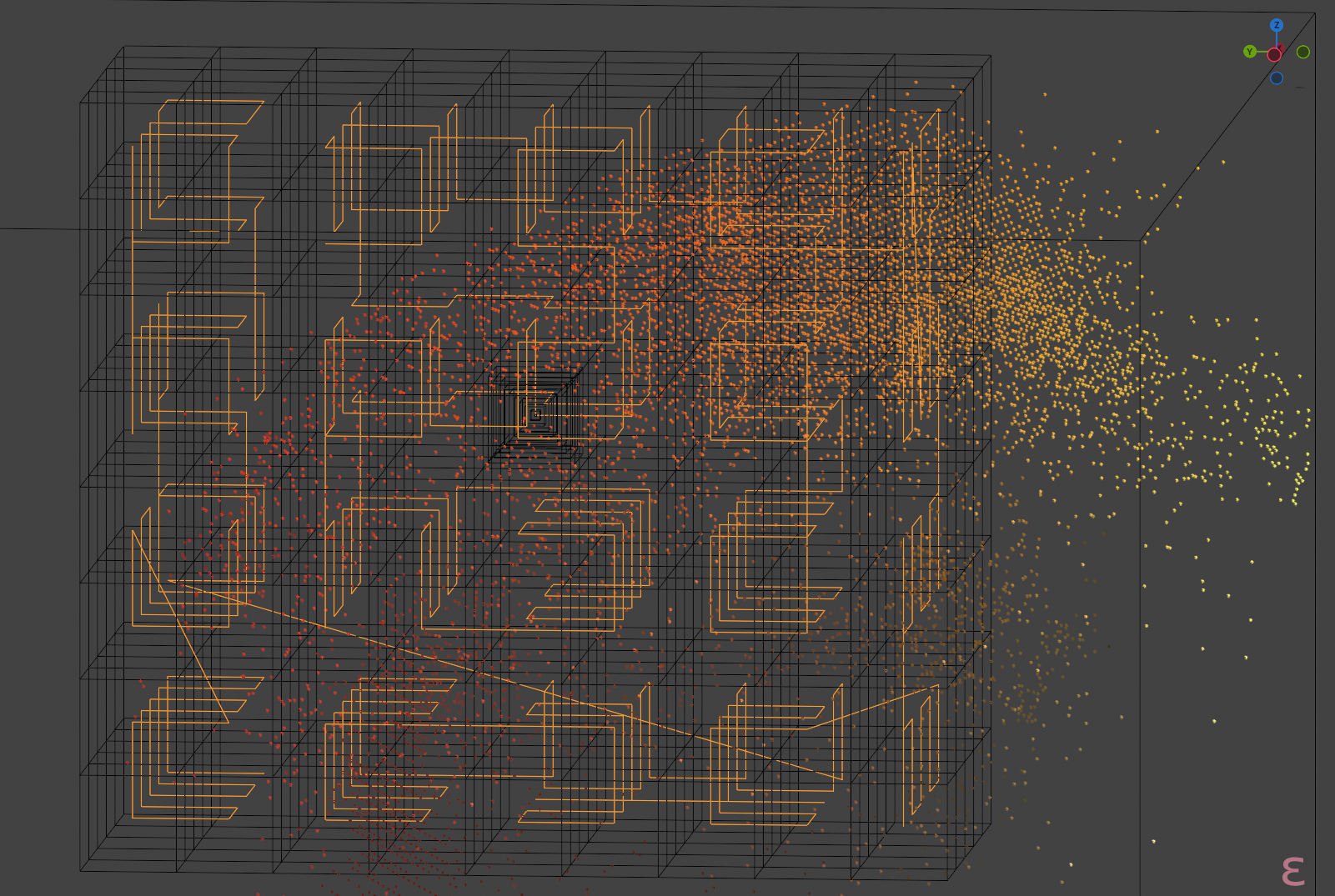
| (colours) | 16'755 | 328'666 | 1'103'347 | ±σ |
|---|---|---|---|---|
copyingin axis order | 2.799ms | 5.744ms | 8.125ms | 279µs/904µs/898µs |
copyingwith GRID_GILBERT | 10.933ms | 15.397ms | 17.391ms | 1.58ms/2.94ms/1.48ms |
so, maybe, only use this order if it'll buy more than it takes:
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...
if known_rgbs > 75_000 {
for (x, y, z) in GRID_GILBERT {
dump(&mut self.buffer_params_map.group_ranges[x][y][z],
& self.groups_accumulator [x][y][z])
}
} else {
for (gr_z, ga_z) in self.buffer_params_map.group_ranges.iter_mut().flatten().flatten()
.zip(self.groups_accumulator .iter() .flatten().flatten()) {
dump(gr_z, ga_z);
}
}
// ...
}
| (colours) | *16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 104.245ms | 6.001s | 106.233s | 2.03ms/12.84ms/1.277s |
| (speed-up vs previous) | 2.88% | 1.17% | 3.44% | |
| (speed-up vs base-line) | 19.34% | 9.16% | — | |
| 5700 XT, [[*freq]] | 86.388ms | 6.579s | 53.748s | 1.82ms/14.82ms/916.9ms |
| (speed-up vs previous) | 36.81% | 1.35% | -1.05% | |
| (speed-up vs base-line) | 28.67% | -51.02% | — | |
| (colours) | *27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 1.566s | 117.119s | 49.116s | 11.14ms/829.3ms/1.62s |
| (speed-up vs previous) | 16.79% | 4.76% | 0.45% | |
| (speed-up vs base-line) | -7.57% | — | — | |
| 5700 XT, [[*freq]] | 574.617ms | 75.128s | 25.529s | 106.6ms/1.748ms/982ms |
| (speed-up vs previous) | -2.95% | 3.32% | -5.71% | |
| (speed-up vs base-line) | -53.88% | — | — | |
| *: slow-down doesn't apply (and subsequent measurement comparisons will ignore it) —: didn't complete before | ||||
![Plot with unlabelled x axis [0, 360] and y axis labelled index [0, 6200]; 'byaxis' looks piecewise-linear, starts around 4500 and climbs with a steady incline between x=0/x=66/x=150/x=220/x=270 but there are large jumps around those discontinuities; bygilbert stays much flatter between x=0/x=230, then jumps less, and this repeats at x=270 and x=340; adjacent_difference(byaxis) and adjacent_difference(bygilbert) are all flattened around y=0 but highlight the large discontinuities](/content/assets/blogn_t/018.36-gilbert-index.png)
![That same plot, with y axis truncated and labelled Δindex [0, 40]; byaxis and bygilbert are unseen; adjacent_difference(byaxis) is 1 with steady bumps up to y=13 every like 10, with larger jumps around the bigger discontinuities; adjacent_difference(bygilbert) stays around y=1 throughout, with smaller fluctuations to around y=4 sometimes and similar off-screen jumps around the big discontinuities](/content/assets/blogn_t/018.37-gilbert-Δindex.png)
gilbert is distributed under the terms of BSD-2-Clause. This doesn't impact our overall 0BSD since neither the code nor its binary form is re-distributed – just the indices, which, as just some data, are not beholden to copyright.
# Totally ellipsoidal, man!
If, instead of iterating the cells intersecting the bounding box of the ellipsoid of interest, only the cells that intersect it are inspected, we can expect the upper bounds of the speed-up to be proportional to the volume of an ellipsoid vs that of its bounding box prism, so [[\frac{V_p}{V_e}]] where heretofore [[V_p = 2R_x2R_y2R_z]] but now [[V_e = \frac{4}{3}\pi R_xR_yR_z]], so [[\frac{8}{\frac{4}{3}\pi} \approx 47.64%]]. (It will be lower because the, uh. "edges" are quantised outward to iterate the whole cell and evaluating the radius bounds themselves itself bears a cost.)
Thus, we seek, for a given point [[q_t]] and radius [[r]], cubic lattice cells that intersect [[r]] around [[q_t]] or are full contained therewithin, which, it seemed natural to me, is equivalent, for cell [[C]] to finding closest-to-[[q_t]] point [[C_c \in C]] furthest-from-[[q_t]] point [[C_f \in C]] such that at least one is inside the radius [[|\overrightarrow{C_cq_t}| \leq r \vee |\overrightarrow{C_fq_t}| \leq r]].
Actually, they're in different coordinate spaces ([[q_t \in P\text{ & }C \in \bar{G}]]) but we have an (almost) bijexion between them so actually [[|\overrightarrow{g^{-1}(C_{c \vee f})q_t}| \leq r]]. [[C]]s laying on a cube lattice makes this computationally quite simple in… most cases, since in those most cases the [[C_c]] and [[C_f]] are opposite corners, so for [[C=(x,y,z)]], [[C_c=(x+[ \kappa],y+[ \lambda],z+[ \mu])]] and [[C_c=(x+[\neg\kappa],y+[\neg\lambda],z+[\neg\mu])]], with [[(\kappa, \lambda, \mu) = (C_x < g(q_t)_x, \cdots)]] and this seems natural and obvious. Doing the comparison in [[P]] space frees us from the burden of figuring out how you'd do it on an ellipsoid post-uneven-[[B_r]] scaling.
Please behold a hateful interactive javascript model of what this would look like in two dimensions. The red point is [[q_t]], point — [[C_c]], blue — [[C_f]]; dark grey cells have neither [[C_{c \vee f}]] inside, yellow ones — one, green — both; [[B_r = (1,1) \Rightarrow g(x) = g^{-1}(x) = x]]:
And just as obvious that this breaks down when one of the coordinates matches, or when [[r]] doesn't include a corner, or when it includes the wrong corner, or
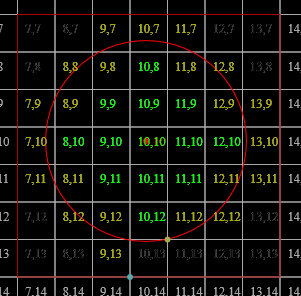
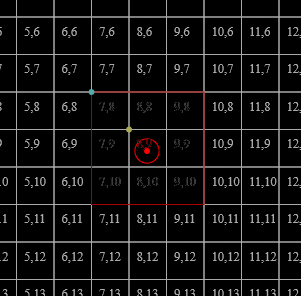
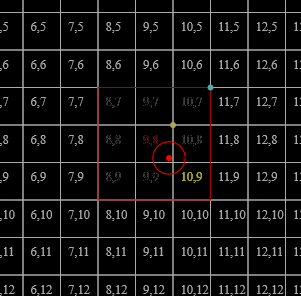
While wrong, it's computationally simple to express
(keeping in mind that < and ! is element-wise):
for(uint iter = 0; iter != iter_limit; ++iter) {
const uint3 gridpos = trunc(lab_to_gridpos(center, bbox_min, bbox_range));
const uint3 gridpos_from = gridpos - min(grid_bothdirs, gridpos);
const uint3 gridpos_to = min(gridpos + grid_bothdirs, GRID_SIZE - 1);
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint gx = gridpos_from.x; gx <= gridpos_to.x; ++gx)
for(uint gy = gridpos_from.y; gy <= gridpos_to.y; ++gy)
for(uint gz = gridpos_from.z; gz <= gridpos_to.z; ++gz) {
const uint3 gxyz = uint3(gx, gy, gz);
bool3 gxyz_close = gxyz < gridpos;
float3 closest_corner = gridpos_to_lab(gxyz + gxyz_close, bbox_min, bbox_range);
float3 furthest_corner = gridpos_to_lab(gxyz + !gxyz_close, bbox_min, bbox_range);
closest_corner -= center;
furthest_corner -= center;
float2 corners_squared = float2(dot(closest_corner, closest_corner),
dot(furthest_corner, furthest_corner));
bool2 corners_inrange = corners_squared <= radiussy_squared;
if(!any(corners_inrange))
continue;
groupdesc_t group = params[0].group_ranges[gx][gy][gz];
// ...
}
newcenter /= newcenter_count;
// ...
}
(with [[g^{-1}]] as gridpos_to_lab)
float3 gridpos_to_lab(float3 pos, float3 bbox_min, float3 bbox_range) {
return (pos / GRID_SIZE) * bbox_range + bbox_min;
}
For of us who have ever experienced 3D geometry the solution may be obvious.
That's not me though.
This
solution
is due to ratchetfreak
(keeping in mind that ?: is also element-wise):
for(uint iter = 0; iter != iter_limit; ++iter) {
const float3 gridpos_f = lab_to_gridpos(center, bbox_min, bbox_range);
const uint3 gridpos = trunc(gridpos_f);
const uint3 gridpos_from = gridpos - min(grid_bothdirs, gridpos);
const uint3 gridpos_to = min(gridpos + grid_bothdirs, GRID_SIZE - 1);
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
for(uint gx = gridpos_from.x; gx <= gridpos_to.x; ++gx)
for(uint gy = gridpos_from.y; gy <= gridpos_to.y; ++gy)
for(uint gz = gridpos_from.z; gz <= gridpos_to.z; ++gz) {
const uint3 gxyz = uint3(gx, gy, gz);
const bool3 gxyz_same = gxyz == gridpos;
bool3 gxyz_close = gxyz < gridpos;
float3 closest_corner = gridpos_to_lab(
gxyz_same ? gridpos_f : (gxyz + gxyz_close), bbox_min, bbox_range);
gxyz_close = gxyz_close || (gxyz_same && (gridpos_to_lab(float3(gxyz) + 0.5, bbox_min, bbox_range) < center));
float3 furthest_corner = gridpos_to_lab(gxyz + !gxyz_close, bbox_min, bbox_range);
closest_corner -= center;
furthest_corner -= center;
float2 corners_squared = float2(dot(closest_corner, closest_corner),
dot(furthest_corner, furthest_corner));
bool2 corners_inrange = corners_squared <= radiussy_squared;
if(!any(corners_inrange))
continue;
groupdesc_t group = params[0].group_ranges[gx][gy][gz];
// ...
}
newcenter /= newcenter_count;
// ...
}
where we observe that [[C_c]] uses [[g(q_t)]]'s components, instead of the corners', on matching axes; [[C_f]] is additionally discriminated, on matching axes, to always pick the corner away from [[q_t]].
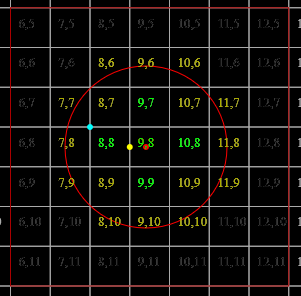
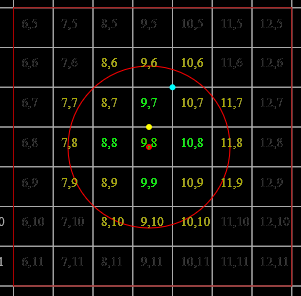
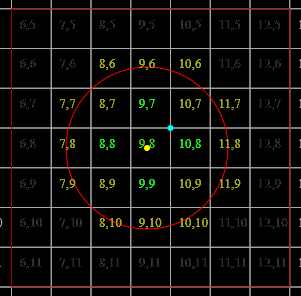
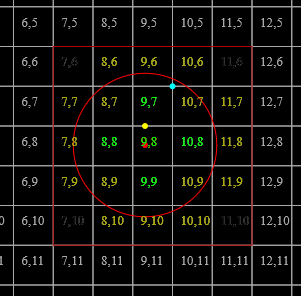
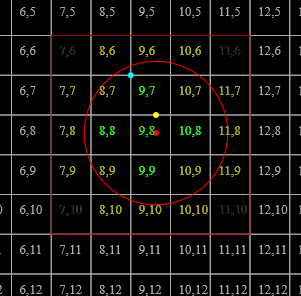
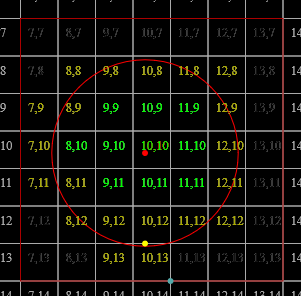
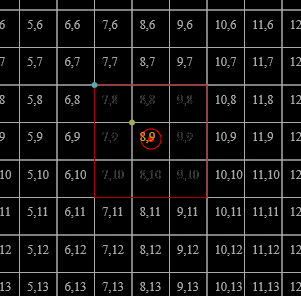
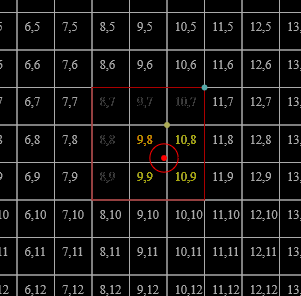
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 95.878ms | 78.837ms | 82.23% |
| (speed-up vs previous) | 10.67% | 42.34% | -45.15 p.p. |
| (speed-up vs base-line) | 25.59% | 33.67% | -10.02 p.p. |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 97.659ms | 125.279ms | 128.28% |
| (speed-up vs previous) | 7.20% | 6.79% | -0.55 p.p. |
| (speed-up vs base-line) | 4.35% | 35.69% | 12.33 p.p. |
and
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 95.878ms | 5.085s | 44.193s | 2ms/13ms/646ms |
| (speed-up vs previous) | 10.67% | 15.26% | 58.40% | |
| (speed-up vs base-line) | 25.59% | 23.02% | — | |
| 5700 XT, [[*freq]] | 78.837ms | 5.904s | 39.274s | 656µs/30ms/2.26ms |
| (speed-up vs previous) | 42.34% | 10.26% | 26.93% | |
| (speed-up vs base-line) | 33.67% | -35.52% | — | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 1.487s | 61.931s | 27.602s | 426ms/1.31s/665ms |
| (speed-up vs previous) | 21.01% | 47.12% | 43.80% | |
| (speed-up vs base-line) | -2.12% | — | — | |
| 5700 XT, [[*freq]] | 406.214ms | 52.312s | 16.861s | 19ms/767ms/13ms |
| (speed-up vs previous) | 27.22% | 30.37% | 33.96% | |
| (speed-up vs base-line) | -8.78% | — | — | |
| —: didn't complete before | ||||
so, around the predicted 47% peak. Cool.
# commutativity can be your angle....
As a side-effect we've classified cells into "ones where no points are within [[r]]", "ones where some points are within [[r]]", and "ones where all points are within [[r]]". In the previous sexion we got to
we can also observe that
but for "cells where all points are within [[r]]" ⇔ [[(\bigwedge_{i \in \texttt{corners_inrange}}i)]] ⇔ [[((x \mapsto [|\overrightarrow{xq_t}| \leq r]) = (x \mapsto 1))]] a [[\sum]] is always the same, and, thus, can be pre-computed. In the same way that skipping iterating the outside bit led to a significant speed-up, this can allow us to skip iterating the inside green bit based on just knowing [[x_g]] (gxyz) if we pre-compute the sum, so.
where [[\sum h(x_g)]] and [[\overline{h(x_g)}]] can both be memoised (and an analogous equivalency can be drawn for [[*freq]]):
struct groupsum_t {
float3 labsum;
uint freqsum;
};
struct params_t {
// ...
groupdesc_t group_ranges [GRID_SIZE] [GRID_SIZE] [GRID_SIZE];
groupsum_t group_sums [GRID_SIZE][GRID_SIZE][GRID_SIZE];
groupsum_t group_mulsums[GRID_SIZE][GRID_SIZE][GRID_SIZE];
};
as computed by sum_cells.kernel.hlsl.inc:
typedef float3 point_t;
#include "shader.h"
[[vk::binding(1)]] RWStructuredBuffer<params_t> params; // DEVICE_LOCAL & HOST_VISIBLE
[[vk::binding(2)]] StructuredBuffer<known_rgbs_pack> known_rgbs_bundle; // DEVICE_LOCAL
[[vk::binding(3)]] StructuredBuffer<uint> known_rgbs_freqs; // DEVICE_LOCAL
[[vk::binding(4)]] StructuredBuffer<uint> groups_data; // DEVICE_LOCAL
[numthreads(1, 1, GRID_SIZE)]
void main(uint3 DTid : SV_DispatchThreadID) {
#define gridpos DTid
groupsum_t sum = {};
groupsum_t mulsum = {};
groupdesc_t group = params[0].group_ranges[gridpos.x][gridpos.y][gridpos.z];
for(; group.start_idx != group.end_idx; ++group.start_idx) {
const uint i = groups_data[group.start_idx];
float3 lab = known_rgbs_bundle[i].lab;
uint freq = known_rgbs_freqs[FREQ_I];
sum.labsum += lab;
sum.freqsum += 1;
mulsum.labsum += lab * freq;
mulsum.freqsum += freq;
}
if(sum.freqsum) {
params[0].group_sums [gridpos.x][gridpos.y][gridpos.z] = sum;
params[0].group_mulsums[gridpos.x][gridpos.y][gridpos.z] = mulsum;
}
}
#define FREQ_I i
#include "sum_cells.kernel.hlsl.inc"
#define FREQ_I known_rgbs_bundle[i].rgb
#include "sum_cells.kernel.hlsl.inc"
as driven by:
// ...
const SUM_CELLS: usize = ASSIGN_CELL + 1;
const SHADER_COUNT: usize = SUM_CELLS + 2;
static SHADER_DATA: [&[u32]; SHADER_COUNT] = [// ...
include_typed!(u32, concat!(env!("OUT_DIR"), "/sum_cells.straight.spv")),
include_typed!(u32, concat!(env!("OUT_DIR"), "/sum_cells.oneshot.spv"))];
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...up to assign_cell.hlsl + grouping + copying
// memcpy(self.buffer_groups_data, self.buffer_outputs, known_rgbs * mem::size_of::<u32>());
// + sum_cells.straight.hlsl or sum_cells.oneshot.hlsl
self.device.cmd_copy_buffer(self.cmd_buffer, self.buffer_outputs.buffer, self.buffer_groups_data.buffer,
&[vk::BufferCopy {
src_offset: 0,
dst_offset: 0,
size: known_rgbs * mem::size_of::<u32>(),
}]);
self.device.cmd_bind_pipeline(self.cmd_buffer, vk::PipelineBindPoint::COMPUTE,
self.compute_pipeline[SUM_CELLS + self.use_oneshot_driver]);
self.device.cmd_dispatch(self.cmd_buffer, GRID_SIZE, GRID_SIZE, 1);
self.submit_buffer(self.cmd_buffer);
}
(note that the shader can be dispatched alongside the previous memcpy for convenience and speed).
This increases params from
[[G^3 \operatorname{sizeof}(\texttt{(uint, uint)}) + \varepsilon \approx 8\text{MB} \approx 3\%]]
to
[[G^3 (\operatorname{sizeof}(\texttt{(uint, uint)}) + 2 \operatorname{sizeof}(\texttt{(float3, uint)})) + \varepsilon \approx 40\text{MB} \approx 15\%]]
so it better be worth it!
(Even though the additional [[32\text{MB}]] doesn't need to be in DEVICE_LOCAL & HOST_VISIBLE at all.)
Time-wise this is immaterial:
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| memcpy | 220.5µs | 268.7µs | 345.5µs | 57µs/64µs/62µs |
| memcpy + sum_cells.hlsl | 244.6µs | 338.8µs | 507.3µs | 56µs/58µs/37µs |
| (cost) | 24µs | 70µs | 162µs | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| memcpy | 248.4µs | 409.5µs | 871.7µs | 27µs/71µs/69µs |
| memcpy + sum_cells.hlsl | 270.9µs | 641.1µs | 1.597ms | 42µs/34µs/30µs |
| (cost) | 22µs | 232µs | 725µs |
if(!any(corners_inrange))
continue;
else if(all(corners_inrange)) {
groupsum_t sums = params[0].SUMS_FIELD[gx][gy][gz];
newcenter_count += sums.freqsum;
newcenter += sums.labsum;
continue;
}
where, expectedly, posterise_grid.hlsl/posterise_grid_oneshot.hlsl:
#define SUMS_FIELD group_sums
and posterise_grid.mul.hlsl/posterise_grid_oneshot.mul.hlsl:
#define SUMS_FIELD group_mulsums
| (colours) | 16'755, [[palette]] | 16'755, [[*freq]] | ([[*freq]]/[[palette]]) |
|---|---|---|---|
| 5700 XT | 68.781ms | 53.958ms | 78.45% |
| (speed-up vs previous) | 39.40% | 46.11% | -3.78 p.p. |
| (speed-up vs base-line) | 46.62% | 54.60% | -13.80 p.p. |
| (colours) | 16'755d, [[palette]] | 16'755d, [[*freq]] | ([[*freq]]/[[palette]]) |
| 5700 XT | 68.856ms | 83.216ms | 120.85% |
| (speed-up vs previous) | 29.49% | 33.58% | -7.42 p.p. |
| (speed-up vs base-line) | 47.43% | 45.20% | -4.90 p.p. |
&
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[palette]] | 68.781ms | 3.242s | 29.624s | 968µs/6.8ms/190ms |
| (speed-up vs previous) | 28.26% | 46.82% | 32.97% | |
| (speed-up vs base-line) | 50.93% | 23.02% | — | |
| 5700 XT, [[*freq]] | 53.958ms | 3.475s | 19.245s | 312µs/15ms/440ms |
| (speed-up vs previous) | 31.56% | 41.15% | 51.00% | |
| (speed-up vs base-line) | 55.45% | 20.25% | — | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 1.154s | 38.160s | 22.638s | 253ms/394ms/1198ms |
| (speed-up vs previous) | 22.34% | 38.38% | 17.98% | |
| (speed-up vs base-line) | 20.70% | — | — | |
| 5700 XT, [[*freq]] | 299.399ms | 30.320s | 12.264s | 2.9ms/381ms/826ms |
| (speed-up vs previous) | 26.30% | 42.04% | 27.26% | |
| (speed-up vs base-line) | 19.82% | — | — | |
| —: didn't complete before | ||||
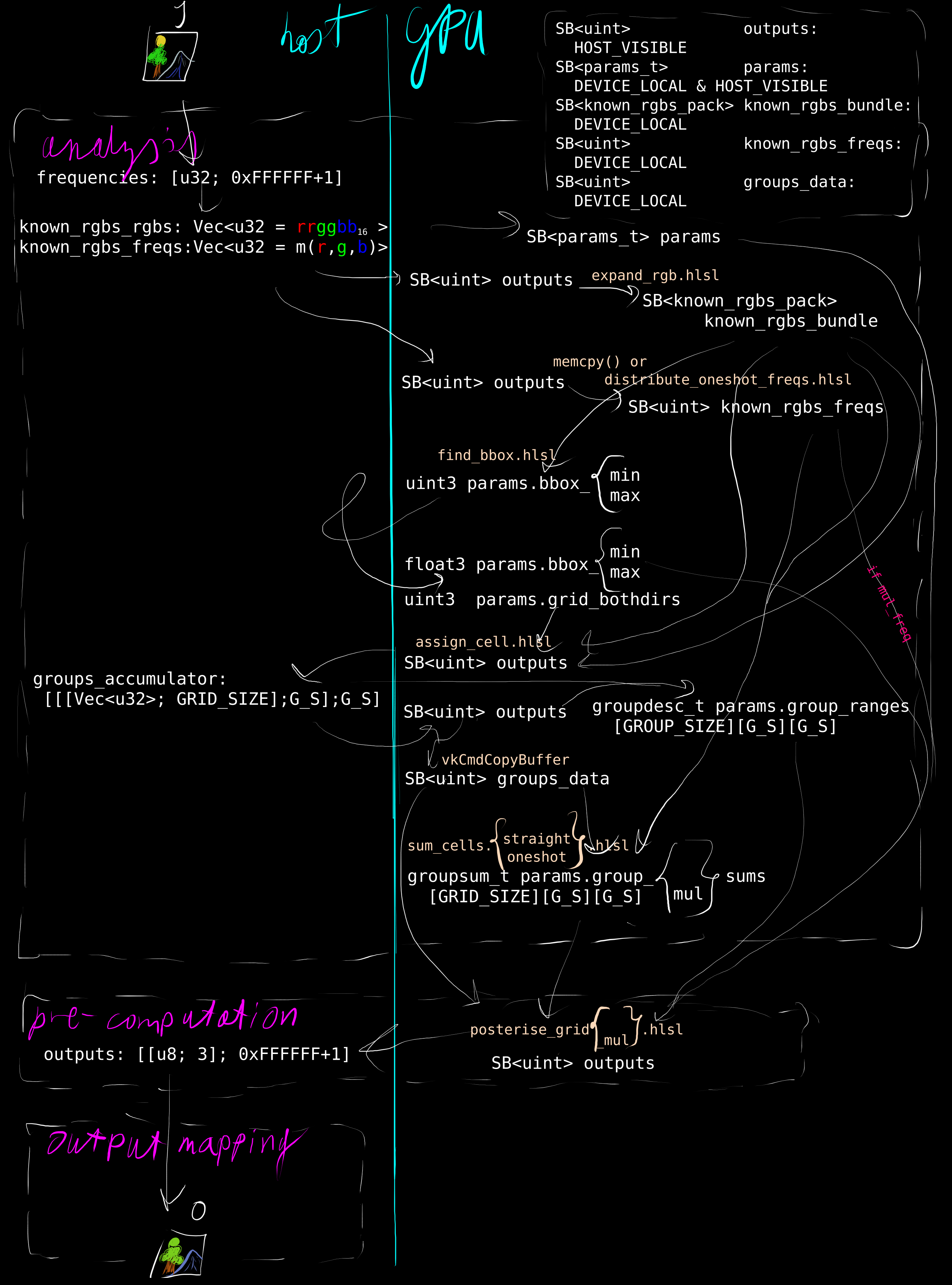
# or yuor devil
The individual values of [[\sum h(x_g)]] go quite a ways away from 0:
| most populous cell, [[palette]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | most populous cell, [[*freq]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | |
|---|---|---|---|---|
| α | ((44.041176, -0.31927294, -0.34573233), | 45) | ((9383.919, -65.55733, -20.474636), | 9434) |
| β | ((58.839714, -0.22819409, -0.020030022), | 60) | ((10189.065, -0.47646168, -0.102591455), | 10203) |
| γ | ((18.17284, 0.18759891, 0.18187594), | 21) | ((39128.875, -0.0036974102, -0.0036974102), | 248129) |
| δ | ((3.2355795, 1.158621, 0.64843106), | 6) | ((0, 0, 0), | 1716920) |
| ε | ((55.92771, -0.81256634, -0.09105891), | 59) | ((6374.0493, 2605.977, -906.254), | 9462) |
| cell with largest [[l]], [[palette]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | cell with largest [[l]], [[*freq]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | |
| α | ((44.041176, -0.31927294, -0.34573233), | 45) | ((9383.919, -65.55733, -20.474636), | 9434) |
| β | ((58.839714, -0.22819409, -0.020030022), | 60) | ((10189.065, -0.47646168, -0.102591455), | 10203) |
| γ | ((18.461334, 0.1365368, 0.25196123), | 20) | ((52687.547, -0.0033568442, 0.0033609867), | 112776) |
| δ | ((3.2355795, 1.158621, 0.64843106), | 6) | ((20940.623, 7498.585, 4196.6367), | 70065) |
| ε | ((55.92771, -0.81256634, -0.09105891), | 59) | ((6374.0493, 2605.977, -906.254), | 9462) |
| cell with largest [[a]], [[palette]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | cell with largest [[a]], [[*freq]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | |
| α | ((8.910748, -1.357208, -0.7054685), | 13) | ((6691.933, -82.91916, -29.420803), | 6763) |
| β | ((2.79438, -0.4932925, 0.46539965), | 4) | ((823.4114, -1.3063359, -0.29277617), | 826) |
| γ | ((10.627919, 0.5354426, 0.28728706), | 13) | ((2371.3867, 629.1607, -65.39355), | 10809) |
| δ | ((3.2355795, 1.158621, 0.64843106), | 6) | ((20940.623, 7498.585, 4196.6367), | 70065) |
| ε | ((3.4370112, 1.2792559, -0.44643825), | 5) | ((6374.0493, 2605.977, -906.254), | 9462) |
| cell with largest [[b]], [[palette]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | cell with largest [[b]], [[*freq]] ([[\sigma_{lab}]], | [[\sigma_{freq}]]) | |
| α | ((31.815504, -0.57158244, -0.95032257), | 34) | ((680.8264, -66.88674, -58.81892), | 982) |
| β | ((3.7039335, -0.46457234, 0.48276806), | 5) | ((107.945366, -0.42522368, 0.8002589), | 117) |
| γ | ((8.998497, 0.1350762, 0.34426308), | 11) | ((21374.111, 178.88039, 555.86554), | 24665) |
| δ | ((2.0014775, -0.1437166, -1.3794196), | 6) | ((7937.199, -569.93335, -5470.323), | 42118) |
| ε | ((15.066136, 0.088873774, 2.2854338), | 17) | ((6374.0493, 2605.977, -906.254), | 9462) |
and especially, since [[P]] is symmetric around 0 in the other axes, in the [[l]] axis. This wouldn't be an issue, except, famously, floats aren't actually commutative, and they're less commutative the further away from 0 they are.
Thus, for the first time, we are bitten by rounding errors: in certain cases, the loop termination condition(s)
if(all(newcenter == center))
break;
// and
if(all(newcenter == center)) {
outputs[this.rgb] = pack_r_g_b_to_rgb(oklab_to_linear_srgb(center));
return;
}
never trigger, and, thus, [[O]] never converges. Frankly, this should've happened earlier, but always adding small numbers is apparently more commutative than adding pre-computed sums of those numbers.
Lightly instrumenting some cells with
printf("{%v3f} {%v3x} => {%v3f} {%v3x} * %d [%v3d]",
center, asuint(center), newcenter, asuint(newcenter),
newcenter_count, newcenter == center);
yields
{0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} => {0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
{0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} => {0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
{0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} => {0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
{0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} => {0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
{0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} => {0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
{0.447506309, -0.000645289, 0.023140611} {3ee51f8c, ba2928a2, 3cbd9161} => {0.447506249, -0.000645289, 0.023140611} {3ee51f8a, ba2928a2, 3cbd9161} * 266? {0, 1, 1}
where we observe a 2-long cycle, where center.l == nextafter(nextafter(newcenter.l)) (2 ULPs off) and v.v..
This can be mitigated by upgrading the [[f]] condition:
float3 prevcenter = -1;
for(;;) {
// ...
newcenter /= newcenter_count;
if(all(newcenter == center) || all(newcenter == prevcenter))
break;
prevcenter = center;
center = newcenter;
}
(FTR I know this is real from posting and IRC logs, but I couldn't re-trigger it when writing the post.)
These speed-ups can be paid into
# re-tuning the piece-meal iteration count
since more than previously can be done without exceeding 8s; a doubling of [[l \mapsto \begin{cases}10 &\text{if}\ l \in [100'000, \infty )\\20 &\text{if}\ l \in [ 10'000, 100'000 )\\\infty &\text{if}\ l \in [ 0, 10'000 )\\\end{cases}]] seems reasonable:
| (colours) | 84'860 | 242'931 | ±σ |
|---|---|---|---|
| 5700 XT, [[palette]] | 3.048s | 31.908s | 6.3ms/591ms |
| (speed-up vs previous) | 5.98% | -7.71% | |
| 5700 XT, [[*freq]] | 3.264s | 21.208s | 12.9ms/959ms |
| (speed-up vs previous) | 6.06% | -10.20% | |
| (colours) | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[palette]] | 39.261s | 20.687s | 413ms/1300ms |
| (speed-up vs previous) | -2.89% | 8.62% | |
| 5700 XT, [[*freq]] | 29.622s | 11.472s | 483ms/471ms |
| (speed-up vs previous) | 2.30% | 6.46% |
Kind of a wash.
# Grid size re-evaluation
is also natural:
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, [[G = 64]] | 58.852ms | ! | 37.512s | 2.49ms/875ms |
| 5700 XT, [[G = 80]] | 64.827ms | 2.983s | 34.030s | 1.96ms/9.01ms/903ms |
| 5700 XT, [[G = 90]] | 66.530ms | 3.000s | 32.443s | 1.97ms/17.5ms/96.4ms |
| 5700 XT, [[G = 100]] | 68.781ms | 3.242s | 29.624s | 968µs/6.8ms/190ms |
| 5700 XT, [[G = 110]] | 81.218ms | 3.122s | 31.146s | 3.94ms/7.95ms/854ms |
| 5700 XT, [[G = 128]] | 95.885ms | 3.870s | 35.580s | 1.94ms/14.39ms/396ms |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, [[G = 64]] | 750.507ms | 45.496s | 27.624s | 52.99ms/460ms/489ms |
| 5700 XT, [[G = 80]] | 958.600ms | 41.959s | 23.934s | 296ms/759ms/767ms |
| 5700 XT, [[G = 90]] | 869.838ms | 41.072s | ! | 5.09ms/414ms |
| 5700 XT, [[G = 100]] | 1.154s | 38.160s | 22.638s | 253ms/394ms/1198ms |
| 5700 XT, [[G = 110]] | 1.500s | 38.148s | 19.301s | 487ms/748ms/735ms |
| 5700 XT, [[G = 128]] | 1.758s | 44.541s | ! | 479ms/815ms |
| !: timed out | ||||
[[G = 100]] stays winning.
# Failure: un-nesting iteration of points-in-cell from iteration of cells-in-bounding-box
[07:23] ratchetfreak: have you considered doing the rejig of the logic I mentioned above, splitting the looking for next shell cell and iterating a shell cell instead of one nested in the other?[20:50] ((наб *)(войд)())(): i don't really see how this is different[20:51] ((наб *)(войд)())(): or, rather, this seems to me like it's exactly the same loop but with two gotos except with the state spilled[21:02] ratchetfreak: it is the same loop but it means that in a warp if one thread is ready to iterate a set of points the rest doesn't have to wait until it's done to continue to the next set instead all threads will continue until they find a cell they need to iterate over and then they together fall into the iteration logic[21:17] ratchetfreak: summerized the most expensive operation in your compute shader is iterating points, so lets make sure that as much as possible no threads in a warp are set to idle when another is iterating their cell
In matters of taste, ye ask and ye shall receive:
for(;;) {
const float3 gridpos_f = lab_to_gridpos(center, bbox_min, bbox_range);
const uint3 gridpos = trunc(gridpos_f);
const uint3 gridpos_from = gridpos - min(grid_bothdirs, gridpos);
const uint3 gridpos_to = min(gridpos + grid_bothdirs, GRID_SIZE - 1);
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
uint3 range = gridpos_to - gridpos_from + 1;
uint need_to_see = range.x * range.y * range.z;
uint seen = 0;
uint3 gxyz;
for(;;) {
bool iter = false;
while(seen < need_to_see) {
seen += 1;
uint acc = seen;
gxyz = gridpos_from;
gxyz.z += acc % range.z;
acc /= range.z;
gxyz.y += acc % range.y;
acc /= range.y;
gxyz.x += acc;
const bool3 gxyz_same = gxyz == gridpos;
// ...
bool2 corners_inrange = corners_squared <= radiussy_squared;
if(!any(corners_inrange))
;
else if(all(corners_inrange)) {
groupsum_t sums = params[0].SUMS_FIELD[gxyz.x][gxyz.y][gxyz.z];
newcenter_count += sums.freqsum;
newcenter += sums.labsum;
} else {
iter = true;
break;
}
}
if(!iter)
break;
groupdesc_t group = params[0].group_ranges[gxyz.x][gxyz.y][gxyz.z];
for(; group.start_idx != group.end_idx; ++group.start_idx) {
// ...
}
}
newcenter /= newcenter_count;
if(all(newcenter == center))
break;
center = newcenter;
}
outputs[this.rgb] = pack_r_g_b_to_rgb(oklab_to_linear_srgb(center));
This is significantly worse than for(uint gx = gridpos_from.x; gx <= gridpos_to.x; ++gx) &c.:
| (colours) | 16'755, [[palette]] |
|---|---|
| 5700 XT | 397.024ms |
| (speed-up vs previous) | × |
| (speed-up vs base-line) | × |
[21:52] ratchetfreak: ah, was worth a shot...[21:53] ((наб *)(войд)())(): no for sure[21:55] ratchetfreak: seen = dot(gxyz, uint3(10000, 100, 1))[21:56] ((наб *)(войд)())(): hm yeah i suppose but only the inverse is of interest right[21:59] ((наб *)(войд)())(): keeping gxyz and bumping .z and propagating overflow had more branches in it when i wrote it[21:59] ((наб *)(войд)())(): but maybe im not branchlesspilled enough[22:02] ratchetfreak: hmm[diff for below][22:04] ((наб *)(войд)())(): zamn[22:06] ratchetfreak: only 1 branch and it's the branch you want to happen[22:08] ratchetfreak: bonus it also avoid the idiv that's typically pretty expensive
uint newcenter_count = 0;
float3 newcenter = float3(0, 0, 0);
uint seen = 0;
uint3 gxyz = gridpos_from - uint3(0, 0, 1);
for(;;) {
bool iter = false;
for(;;) {
bool3 wrap = gxyz >= gridpos_to;
if(all(wrap))
break;
bool wrapz = wrap.z;
bool wrapy = wrap.z && wrap.y;
bool3 nil = bool3(false, wrapy, wrapz);
gxyz = nil ? gridpos_from : (gxyz + uint3(wrapy, wrapz, 1));
const bool3 gxyz_same = gxyz == gridpos;
// ...
| (colours) | 16'755, [[palette]] |
|---|---|
| 5700 XT | 397.024ms |
| (speed-up vs above) | 50.80% |
| (speed-up vs previous) | × |
| (speed-up vs base-line) | × |
[22:25] ((наб *)(войд)())(): also funny, too me, that you've reimplemented wrapping addition combinatorially to solve what is otherwise a very mundane problem[22:26] ratchetfreak: wrapping addition with carry lookahead
# Failure: [[l<a<b]]
[14:54] ratchetfreak: for example a very flat in the z-axis data set (max_z - min_z < radius) will have a gr_z == 100 and always iterate the full depth of the grid on each particle[14:55] ((наб *)(войд)())(): this will always be the case[14:56] ((наб *)(войд)())(): if you need to look at the whole z-axis then you need to look at the whole z-axis[14:56] ratchetfreak: but if it's flat in the x axis it will need to deal with 2 more inner loops[14:57] ratchetfreak: so a rotation of the data set might be in order so the flattest axis is always z[14:57] ratchetfreak: that way the longest inner loop is inside
so, obtusely (there has to be a better, perhaps even canonical, way of expressing this):
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...find_bbox.hlsl
let mut bbox_min = become_float3(&self.buffer_params_map.bbox_min);
let mut bbox_range = {
let bbox_max = become_float3(&self.buffer_params_map.bbox_range);
[bbox_max[0] - bbox_min[0], bbox_max[1] - bbox_min[1], bbox_max[2] - bbox_min[2]]
};
// Sort coordinates so the bounding box ranges are x>y>z
// such that the grid radiussy bounding prism is x<y<z such that the innermost loop is the hottest
let mut swaps = [0, 1, 2];
let mut unswaps = [0, 1, 2];
if bbox_range[0] < bbox_range[2] {
bbox_min .swap(0, 2);
bbox_range.swap(0, 2);
swaps .swap(0, 2);
}
if bbox_range[1] < bbox_range[2] {
bbox_min .swap(1, 2);
bbox_range.swap(1, 2);
swaps .swap(1, 2);
unswaps .swap(1, 2);
}
if swaps[0] != 0 {
unswaps.swap(0, 2);
}
self.buffer_params_map.bbox_min = bbox_min;
self.buffer_params_map.bbox_range = bbox_range;
self.buffer_params_map.axis_swaps = ((( swaps[0] << 4) | ( swaps[1] << 2) | ( swaps[2] << 0)) << 8)
| (((unswaps[0] << 4) | (unswaps[1] << 2) | (unswaps[2] << 0)));
// assign_cell.hlsl...
}
struct params_t {
// ...
point_t bbox_range;
uint axis_swaps;
#define bbox_max bbox_range
// ...
};
such that assign_cell.hlsl can rotate the axes:
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const float3 bbox_min = params[0].bbox_min;
const float3 bbox_range = params[0].bbox_range;
const uint axis_swaps =(params[0].axis_swaps >> 8) & 0xFF;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
#define TWOBITS 3
float3 lab = known_rgbs_bundle[id].lab;
lab = float3(lab[(axis_swaps >> 4)],
lab[(axis_swaps >> 2) & TWOBITS],
lab[(axis_swaps >> 0) & TWOBITS]);
known_rgbs_bundle[id].lab = lab;
uint3 gridpos = trunc(lab_to_gridpos(lab, bbox_min, bbox_range));
outputs[id] = (gridpos.x << (8 * 2)) |
(gridpos.y << (8 * 1)) |
(gridpos.z << (8 * 0));
}
and posterise_grid.kernel.hlsl.inc/posterise_grid_oneshot.kernel.hlsl.inc can unrotate them when uploading outputs:
#define TWOBITS 3
outputs[this.rgb] = pack_r_g_b_to_rgb(oklab_to_linear_srgb(
float3(center[(axis_unswaps >> 4)],
center[(axis_unswaps >> 2) & TWOBITS],
center[(axis_unswaps >> 0) & TWOBITS])));
since everything else is [[P]]-agnostic.
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
| 5700 XT, natural | 68.781ms | 3.242s | 29.624s | 968µs/6.8ms/190ms |
| 5700 XT, l<a<b | 69.741ms | 3.057s | 32.232s | 2.17ms/11.1ms/780ms |
| 5700 XT, l>a>b | 71.622ms | 3.143s | 34.152s | 2.06ms/7.73ms/2.061s |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
| 5700 XT, natural | 1.154s | 38.160s | 22.638s | 253ms/394ms/1198ms |
| 5700 XT, l<a<b | 1.374s | 39.296s | 20.306s | 487ms/819ms/641ms |
| 5700 XT, l>a>b | 1.401s | 39.200s | 20.292s | 487ms/827ms/768ms |
Pretty much every operation that could be parallelised so far has been so how's about
# parallelising is points-in-cell assign_cell.hlsl grouping
post-processing
pub struct PosteriseGpu {
// ...
groups_accumulator: Box<[[[sync::Mutex<Vec<u32>>; GRID_SIZE]; GRID_SIZE]; GRID_SIZE]>,
use_oneshot_driver: bool,
}
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
ret.groups_accumulator = Box::<mem::MaybeUninit<_>>::assume_init(Box::new_uninit()),
for ga in ret.groups_accumulator.iter_mut().flatten().flatten() {
ptr::write(ga as *mut _, sync::Mutex::new(Vec::new()));
}
// ...
}
fn PosteriseGpu::measure(&mut self, known_rgbs_rgbs: &[u32], known_rgbs_freqs: &[u32]) {
// ...assign_cell.hlsl
// grouping
let known_rgbs_groupcoords: &mut [u32] = &self.buffer_outputs_map[0..known_rgbs];
let threads = num_cpus::get();
let setlen_default = known_rgbs_groupcoords.len() / threads;
let setlen_last = known_rgbs_groupcoords.len() - setlen_default * (threads - 1);
for group in self.groups_accumulator.iter_mut().flatten().flatten() {
group.get_mut().unwrap().clear();
}
let mut joins = Vec::with_capacity(threads);
for subset in 0..threads {
let setlen = if subset == threads - 1 { setlen_last }
else { setlen_default };
let known_rgbs_groupcoords: &'static [_] =
slice::from_raw_parts (known_rgbs_groupcoords [..].as_ptr(), known_rgbs_groupcoords.len());
let groups_accumulator: &'static mut [_] =
slice::from_raw_parts_mut(self.groups_accumulator[..].as_mut_ptr(), self.groups_accumulator.len());
joins.push(thread::spawn(move || {
for (id, groupcoord) in known_rgbs_groupcoords[subset * setlen_default..subset * setlen_default + setlen].iter().enumerate() {
let id = id + subset * setlen_default;
let (x, y, z) = ((groupcoord >> (8 * 2)),
(groupcoord >> (8 * 1)) & 0xFF,
(groupcoord >> (8 * 0)) & 0xFF);
groups_accumulator[x][y][z].lock().unwrap().push(id);
}
}));
}
joins.into_iter().for_each(|jh| jh.join().unwrap());
// copying
let mut dump = /* ... */;
let mut cur = 0;
if known_rgbs > 75_000 {
for (x, y, z) in GRID_GILBERT {
dump(&mut self.buffer_params_map.group_ranges[x][y][z],
& self.groups_accumulator [x][y][z].get_mut().unwrap())
}
} else {
for (gr_z, ga_z) in self.buffer_params_map.group_ranges.iter_mut().flatten().flatten()
.zip(self.groups_accumulator .iter() .flatten().flatten()) {
dump(gr_z, ga_z.get_mut().unwrap());
}
}
// sum_cells.straight.hlsl or sum_cells.oneshot.hlsl...
}
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
i7-2600, grouping, serial | 4.453ms | 11.115ms | 23.344ms | 327µs/686µs/1.847ms |
i7-2600, grouping, 8 threads | 5.275ms | 7.067ms | 9.819ms | 634µs/788µs/1.865ms |
i7-2600, copying, serial | 2.763ms | 11.469ms | 12.275ms | 209µs/1.256ms/825µs |
i7-2600, copying, 8 threads | 3.461ms | 14.873ms | 15.560ms | 478µs/1.780ms/1.557ms |
| (speed-up) | -21.07% | 2.86% | 28.75% | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
i7-2600, grouping, serial | 5.699ms | 31.908ms | 94.578ms | 699µs/1.523ms/8.194ms |
i7-2600, grouping, 8 threads | 5.178ms | 11.376ms | 24.370ms | 507µs/1.869ms/5.247ms |
i7-2600, copying, serial | 2.937ms | 14.389ms | 16.953ms | 323µs/1.111ms/1.347ms |
i7-2600, copying, 8 threads | 3.327ms | 17.073ms | 20.331ms | 221µs/1.382ms/836µs |
| (speed-up) | 1.52% | 38.55% | 59.92% |
That's a lot of locking and unwraps, and the threads holding the mutexes can never panick, so the unwraps are always successful, so maybe… just assume the unwrap always succeeds?
| (colours) | 16'755 | 84'860 | 242'931 | ±σ |
|---|---|---|---|---|
i7-2600, grouping, 8 threads, .unwrap_unchecked() | 5.118ms | 6.712ms | 8.808ms | 534µs/821µs/1.078ms |
i7-2600, copying, 8 threads, .unwrap_unchecked() | 3.431ms | 12.855ms | 13.936ms | 491µs/1.278ms/657µs |
| (speed-up vs serial) | -18.47% | 13.36% | 36.15% | |
| (speed-up vs serial) | 2.60 p.p. | 10.50 p.p. | 7.40 p.p. | |
| (speed-up vs 8 threads) | 2.15% | 10.81% | 10.38% | |
| (colours) | 27'868 | 328'666 | 1'103'347 | ±σ |
i7-2600, grouping, 8 threads, .unwrap_unchecked() | 5.148ms | 11.655ms | 25.468ms | 450µs/2.112ms/5.812ms |
i7-2600, copying, 8 threads, .unwrap_unchecked() | 3.353ms | 16.309ms | 20.246ms | 368µs/1.725ms/1.636ms |
| (speed-up vs serial) | 1.56% | 39.60% | 59.01% | |
| (speed-up vs serial) | 0.04 p.p. | 1.05 p.p. | -0.91 p.p. | |
| (speed-up vs 8 threads) | 0.04% | 1.71% | -2.26% |
Not great, not terrible, for the cost of bumping groups_accumulator from is a similar size to the [[8\text{MB}]] — [[G^3 \cdot \operatorname{sizeof}(\texttt{Mutex<Vec<_>>}) = G^3 \cdot (3 \operatorname{sizeof}(\texttt{usize}) + m) = 32\text{MB}_{\text{LP64}} \vee 20\text{MB}_{\text{ILP32}_\text{linux}} \vee 16\text{MB}_{\text{ILP32}_\text{Win32}}]] (from[[\ 24\text{MB}_\text{LP64} \vee 12\text{MB}_\text{ILP32}]]).
Conversely,
# de-parallelising find_bbox.hlsl
was also in order. I'd actually had it marked "TODO: groupshared?" in the original implementation but there is no documentation or extant implementation using group-shared memory that makes sense. One'd think that a reduction would be perfect for it, but… no?
What would also have the desired effect of doing fewer atomics to real memory is "reducing across the subgroup and doing the atomic in the elected thread in a subgroup" (Vulkan/GLSL nomenclature) or "reducing across the wave and doing the atomic in the first lane in a wave" (HLSL nomenclature). I think it's the bit that's 64 (or 32 on nvidia cards)? They also call it a warp sometimes? Also the election always chooses the first "thread", so. Hardly an "election"? So, find_bbox.hlsl:
[numthreads(64, 1, 1)]
void main(uint3 DTid : SV_DispatchThreadID) {
const uint known_rgbs_len = params[0].known_rgbs_len;
const uint id = DTid.x;
if(id >= known_rgbs_len)
return;
uint3 tmp = known_rgbs_bundle[id].lab;
tmp ^= (~(tmp >> 31) + 1) | 0x80000000;
uint3 m = WaveActiveMin(tmp);
uint3 M = WaveActiveMax(tmp);
if(WaveIsFirstLane()) {
InterlockedMin(params[0].bbox_min.x, m.x);
InterlockedMin(params[0].bbox_min.y, m.y);
InterlockedMin(params[0].bbox_min.z, m.z);
InterlockedMax(params[0].bbox_max.x, M.x);
InterlockedMax(params[0].bbox_max.y, M.y);
InterlockedMax(params[0].bbox_max.z, M.z);
}
}
but this fails to compile with
shaderc: internal error: compilation succeeded but failed to optimize: Capability GroupNonUniform is not allowed by Vulkan 1.0 specification (or requires extension)
OpCapability GroupNonUniform
This doesn't mean you need to enable an extension in your Vulkan run-time (since it's not even getting to that point).
It doesn't mean you need to enable an extension in glslc
(though those are a real thing! mostly in GLSL, but they're also part of the SPIR-V output.
There may be some way to enable the SPIR-V ones if you find a mapping from the official featureextension name you want.
I behoove the dear reader to find anything relevant to this in glslc(1),
which uses "extension" mostly to mean the file-name suffix and also some-times to mean GL_GOOGLE_cpp_style_line_directive
which is part of preprocessor support).
What it actually means is that you need to bump the base-line to a Vulkan version that has non-uniform/warp/wave/subgroup operations.
How do you do that?
You guessed it!:
glslcs.push(std::process::Command::new("glslc")
.arg("--target-env=vulkan1.2")
It may also be apt to validate this is supported (though it is likely also an over-abundance of caution), which can only be queried by asking for the physical device properties… next 2 the subgroup properties. 🙄
fn PosteriseGpu::init() -> PosteriseGpu {
// ...
let mut physical_device_subgroup_properties = vk::PhysicalDeviceSubgroupProperties::builder();
let mut physical_device_properties2 = vk::PhysicalDeviceProperties2::builder().push_next(&mut physical_device_subgroup_properties);
vk_instance.get_physical_device_properties2(physical_device, &mut physical_device_properties2);
let physical_device_properties = physical_device_properties2.build().properties;
assert!(SHADER_MAX_BINDING < physical_device_properties.limits.max_bound_descriptor_sets);
let physical_device_subgroup_properties = physical_device_subgroup_properties.build();
let need = vk::SubgroupFeatureFlags::BASIC | vk::SubgroupFeatureFlags::ARITHMETIC;
assert!(physical_device_subgroup_properties.supported_operations & need == need);
// ...
}
BASIC | ARITHMETIC
are required by
OpGroupNonUniformElect
and
OpGroupNonUniformUMin/Max,
respectively, and that's what spirv-dis says the shader compiles to.
| (colours) | 16'755 | 1'103'347 | ±σ |
|---|---|---|---|
| 5700 XT, natural | 74.897µs | 156.374µs | 20µs/81µs |
| 5700 XT, wavy | 76.884µs | 141.892µs | 20µs/59µs |
| (speed-up) | -2.65% | 9.26% |
Placebo optimisation. Maybe it's better on worse hardware.
# Moral
Don't develop software for the GPU. Don't try to create 3D models. Never attempt to use vaguely novel technology, implement a paper, or advance the field.
Avoid documenting or formalising anything, especially to describe or measure methodology.
Accd'g to the post I threaded under,
I started around
# Network effect
2025-02-17 gfx-rs/wgpu#7164: Fix examples links in README-
# KyleMayes/vulkanalia:
2025-02-17 #311: App:[:]create2025-02-22 #312: queue_wait_idle() returns Err(ErrorCode(2)) which it doesn't know how to format and resorts to just "2". is this SuccessCode::TIMEOUT (2)?2025-02-22 #313: All upstream documentation links are 404s2025-02-22 #314: Fix upstream links being 404s by linking to /latest/ instead of /1.4-extensions/2025-02-23 #315: ShaderModuleCreateInfoBuilder takes .code(&[u32]) but then .code_size() in bytes, should probably just take .code(&[u32]) and derive code_size automatically2025-02-23 #316: Use Result's Debug and Display implementations for SuccessCode and ErrorCode2025-02-24 #320: ShaderModuleCreateInfoBuilder::code() sets both code and code_size, remove its ::code_size()2025-02-24 #321: resetting command buffers, not pools
2025-02-25 google/shaderc#1484: Missed optimisation: doesn't elide <<0/-0/>>0/|0 like it does +02025-02-25 KhronosGroup/SPIRV-Tools#6013: optimiser: remove OpBitwiseOr OpBitwiseXor OpShiftRightLogical OpShiftRightArithmetic OpShiftLeftLogical OpIAdd OpFAdd OpISub OpFSub with 0 or vec[any](0) on rhs and OpBitwiseOr OpBitwiseXor OpIAdd OpFAdd on lhs2025-02-28 KhronosGroup/SPIRV-Tools#6020: Fold 0 <<,>>,/,% n to 0. Fold a / 1 to a. Fold a % 1 to 0. Fold f % 1.0 to 0.0. Fold 0.0 % f to 0.02025-02-26 jakubcerveny/gilbert#17: Port to Rust-
# rust-lang/rust:
2025-02-23 #137490: What does "before-main stdio file descriptors are not guaranteed to be open on unix platforms" mean?2025-02-23 #137492: libstd: rustdoc: correct note on fds 0/1/2 pre-main2025-02-23 #137493: configure.py: don't instruct user to run nonexistent program2025-02-23 #137494: libstd: init(): dup() subsequent /dev/nulls instead of opening them again2025-02-23 #137499: nightly cargo can no longer build anything due to error: failed to create directory `...\target` Caused by: Incorrect function. (os error 1)2025-02-24 #137547: Revert 00bf74da6d1e8e49b18c0203e0cbd993fdac56632025-02-26 #137678: 1 million item array spends inordinate time on error path of typechecking2025-02-26 #137680: Dumps unbounded amounts of data in diagnostics (27M in three lines for one error!) for large input lines (and thinks about them for minutes first)2025-02-26 #137681: Deleting newlines from input makes it build 3% faster end-to-end2025-03-25 #138953: f32 += f32 * u32 is faster in a loop than f32 += f32; can be defeated (a little bit) with #[cold] annotation?
-
# ~sircmpwn/sourcehut:
2025-03-05 ~sircmpwn/git.sr.ht#380: Renaming private repository leaks old and new names into redirect table queriable at unlisted-equivalent visibility2025-03-06 [PATCH git.sr.ht] Add git.sr.ht-http-clone to intercept git http-backend explicitly and provide redirections2025-03-06 [PATCH sr.ht-docs] git.sr.ht: use git.sr.ht-http-clone2025-03-06 [PATCH git.sr.ht] shell: return "Access denied." for redirects to private repositories the pusher can't access2025-03-10 [PATCH core-go] client: make InternalAuth.Name omitempty to allow @anoninternal auth2025-03-11 [PATCH builds.sr.ht] Use git -C/hg --cwd instead of cd &&2025-04-10 [PATCH git.sr.ht 1/4] commit: range(max(a, b))+if(i >= a || i >= b)break => range(min(a, b))2025-04-10 [PATCH git.sr.ht 2/4] commit: use saved variables for old_path/new_path2025-04-10 [PATCH git.sr.ht 3/4] commit: detect common suffix in addition to prefix2025-04-10 [PATCH git.sr.ht 4/4] commit: also link renames2025-04-10 [PATCH lists.sr.ht] patchset: accumulate authors correctly instead of undecoded
2025-03-19 Rust-SDL2/rust-sdl2#1468: Fix SDL_PIXELFORMAT_{RGBA,ARGB,BGRA,ABGR}32 being backward on big-endian targets2025-03-30 pygments/pygments#2881: Guesses HLSL code as "tsql" instead of HLSL/C/C++ despite "tsql" yielding errors-
# mathjax/MathJax:
2025-03-16 #3342: AsciiMath input partially explodes on matrices, TeX handles them fine2025-03-16 #3343: AsciiMath turns f(\(a, b\)) into f(a b)a, b)?2025-03-17 #3344: Matrices render goofy in CHTML, fine with SVG2025-03-17 #3345: Opening page with SVG renderer explodes the parser on \color statements; setting to CHTML and reloading works, and then setting to SVG draws mostly-correctly2025-04-06 #3354: ^F search highlight broken2025-04-06 #3355: ^F search "whole word" mode broken2025-04-08 #3357: \overline displayed varyingly as an overline or as nothing depending on font size
2025-03-27 #1101435: /usr/bin/pyftsubset: ModuleNotFoundError: No module named 'zopfli' with --flavor=woff2025-03-28 Bug 1957125: Link/object bounding box no longer matches the reality of the link/object2025-03-30 Bug 1957298: When updating URL with #:~:text= anchor, highlight is added for the new referenced text, but it does not replace the previous ones2025-04-11 Bug 1960124: "data:text/html,<table><caption>a<caption>b<td>c</table>" renders only a\nc — more than 1display: table-caption;element is eaten2025-04-16 Bug 1960952: Ctrl+H creates history menu, then Ctrl+H again doesn't make the menu go away2025-04-22 Bug 1961886: Table <caption> children aren't focusable with Tab2025-03-30 PrismJS/prism#3881: HLSL #define not highlighted right (... or indeed overhighlighted): uniform .token.property applies, washing out the expression-
# blender/blender:
2025-03-31 #136787: Default EEVEE renderer crashes-to-desktop when opening Material or Shading tabs2025-03-31 #136788: 4.4.0 doesn't start at all2025-04-01 #136803: Partially parse AMD driver versions to determine if they require legacy work-arounds instead of spot-checking2025-04-01 #136839: Fix Makefile error erroring without the error message on Win322025-04-07 #137112: The input map at the bottom of the screen doesn't indicate you can write Δxyz directly in Move operation (nothing else does, either, but this is where you'd expect it)2025-04-07 #137113: Impossible to tab backward when writing Δxyz directly in Move operation2025-04-08 #137124: Fix #137113: bind universal Shift+Tab to go back instead of Ctrl+Tab2025-04-11 #137357: Minimum accepted OpenColorIO, wayland-protocols, libvulkan-dev, OpenImageIO versions too low?2025-04-18 #137749: Keyframes appear and disappear in the Timeline window depending on where the scrub head is, no filters applied
2025-04-12 servo/servo#36480: Links stop being links when... big page? or maybe some javascript?2025-04-12 servo/servo#36481: Crashes for a bit then segfaults on MathJax-heavy page (also cites min-/max-content size. idk)2025-04-22 servo/servo#36650: Segfaults on exit based on page contents(?) on Win322025-04-13 matplotlib/matplotlib#29912: [Bug]: findfont: Font family '<font>' not found. despite being present and queriable via fontconfig; never makes it to ~/.cache/matplotlib/fontlist-v330.json either2025-04-13 matplotlib/matplotlib#29913: [Bug]:plt.ticklabel_format(style='plain')puts the y axis label out of frame2025-04-28 Bug 503481: Moving cursor around in-image WYSIWYG copies text colour under cursor to everything else2025-04-28 Bug 503482: Subscript doesn't render correctly
Bonus bugs from writing the post:
Nit-pick? Correction? Improvement? Annoying? Cute? Anything?
Mail,
post, or open!